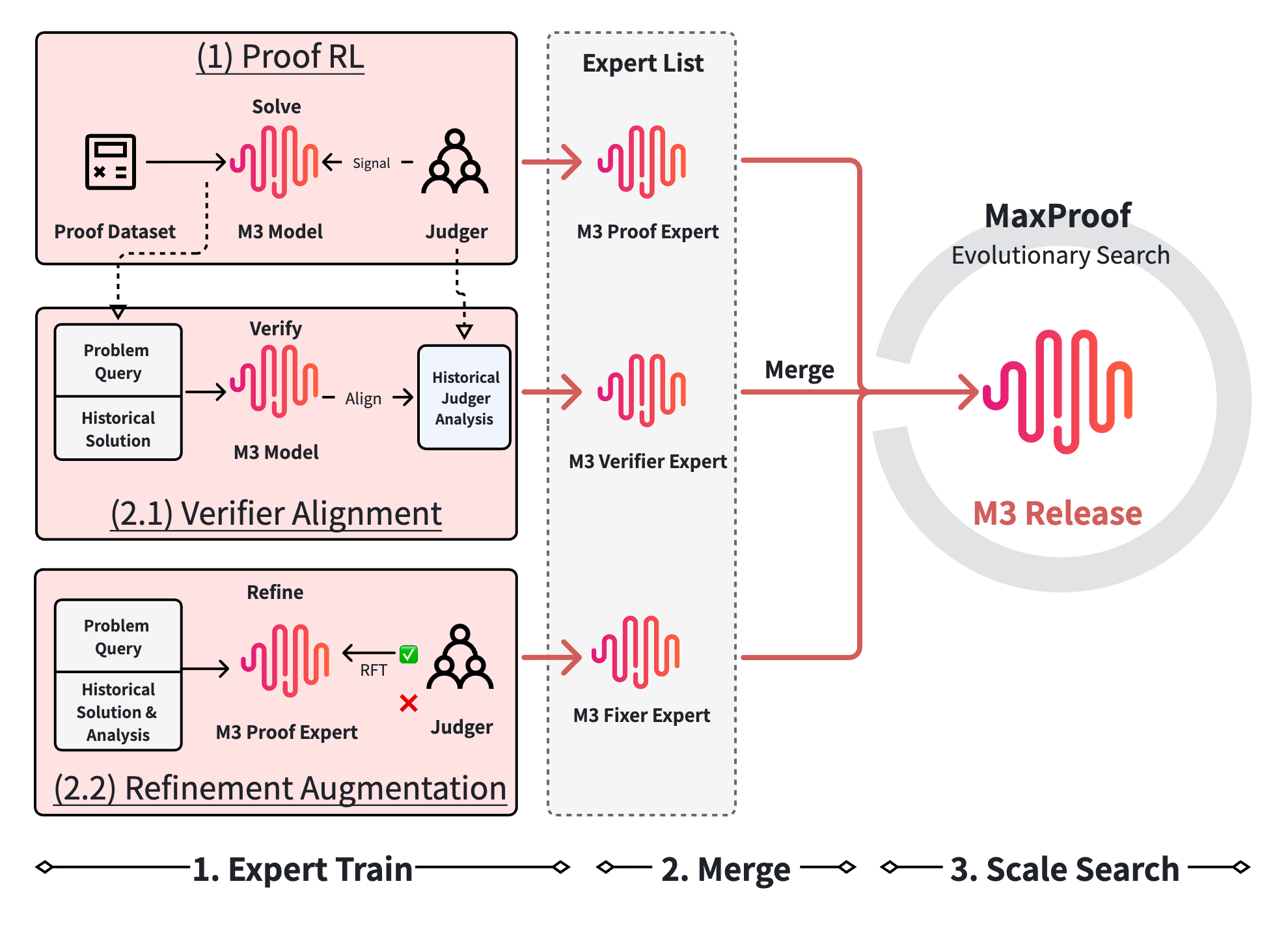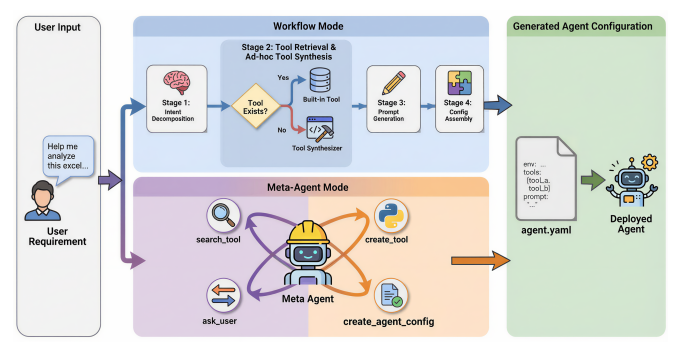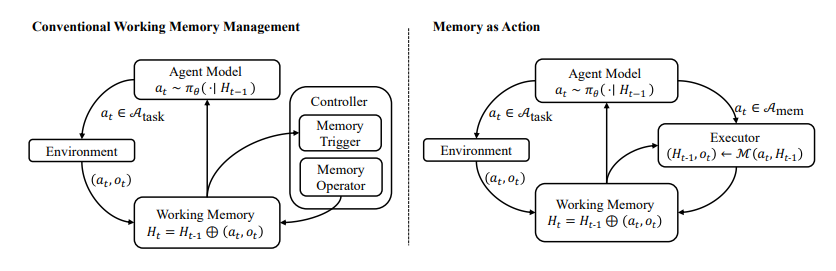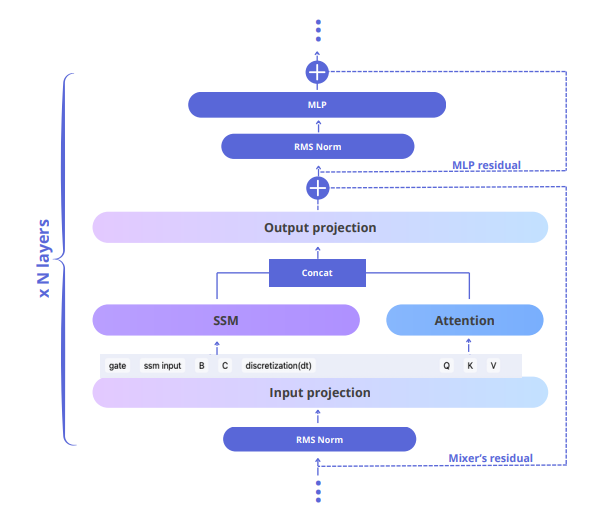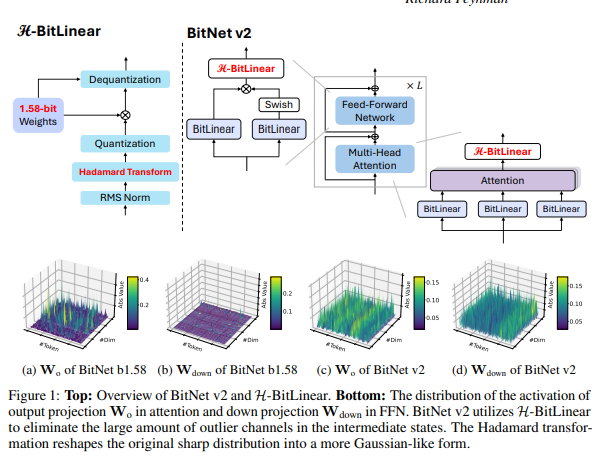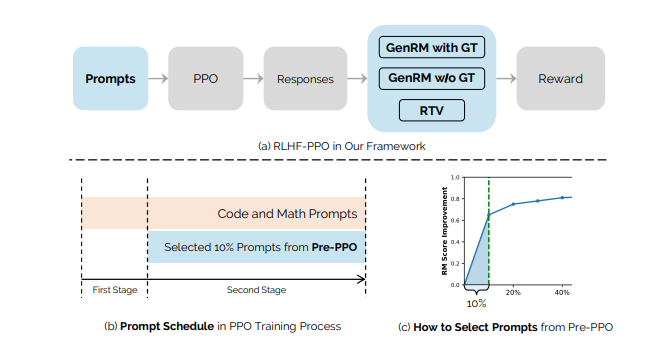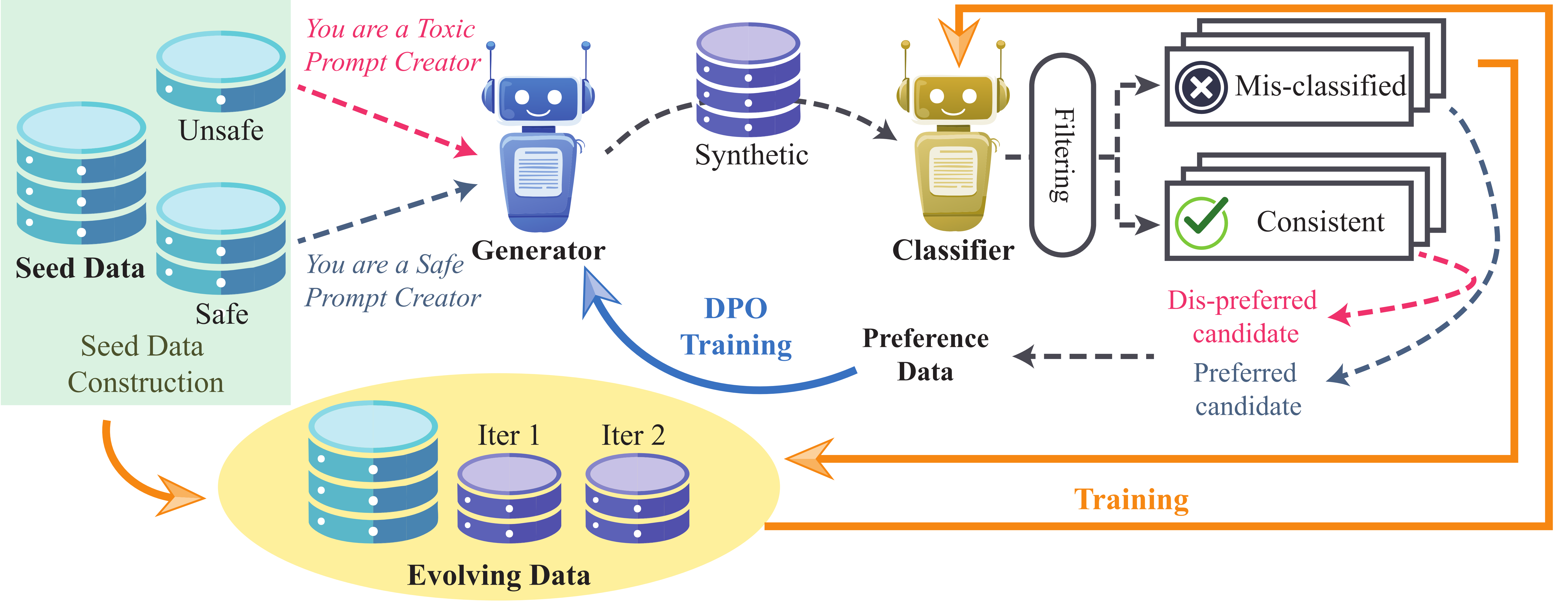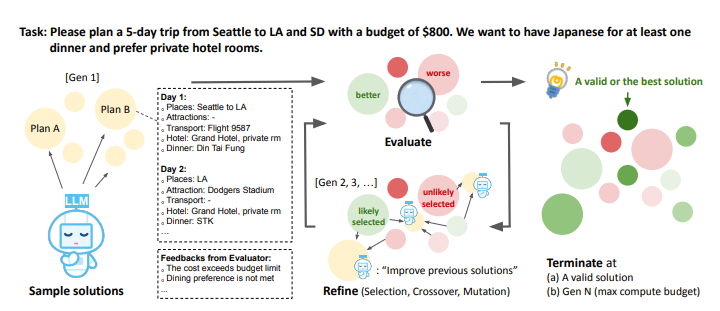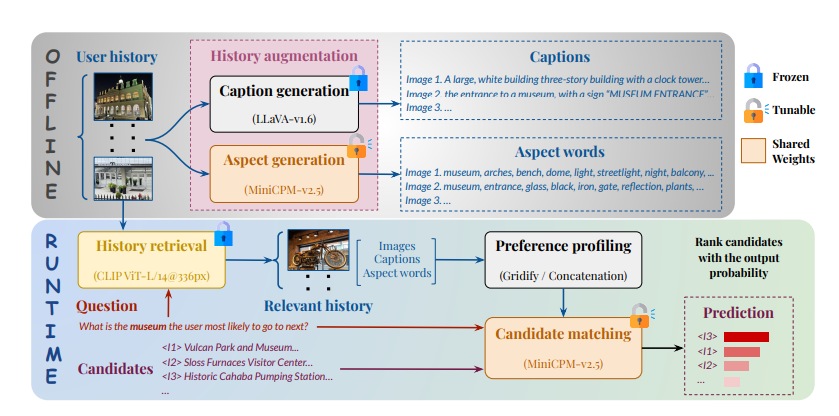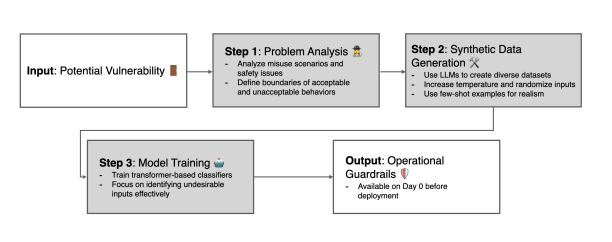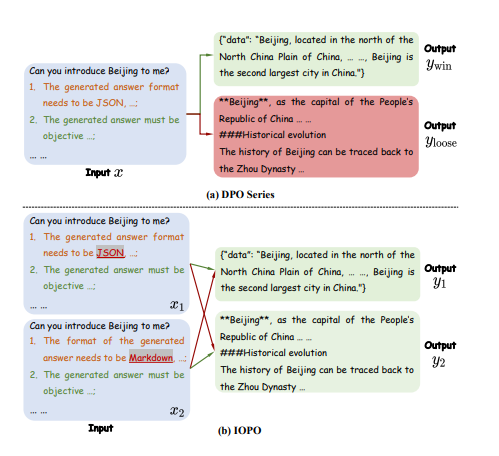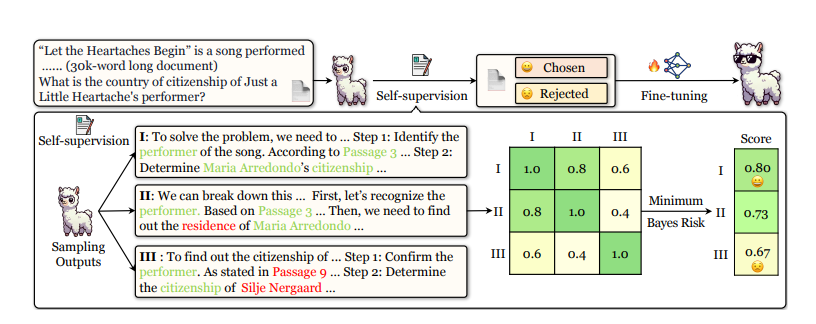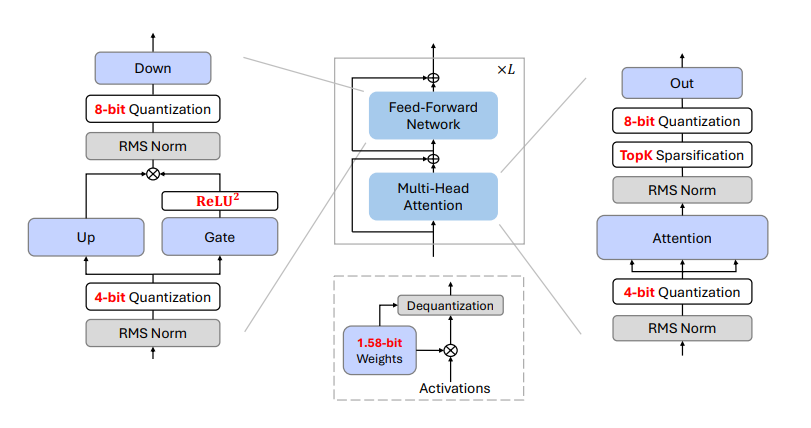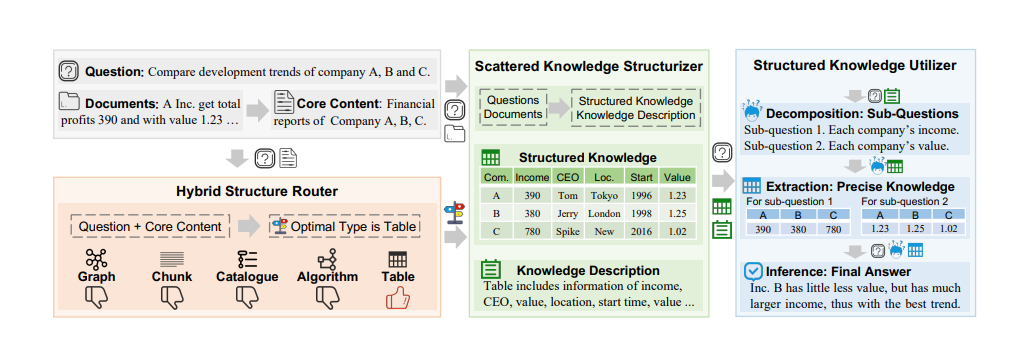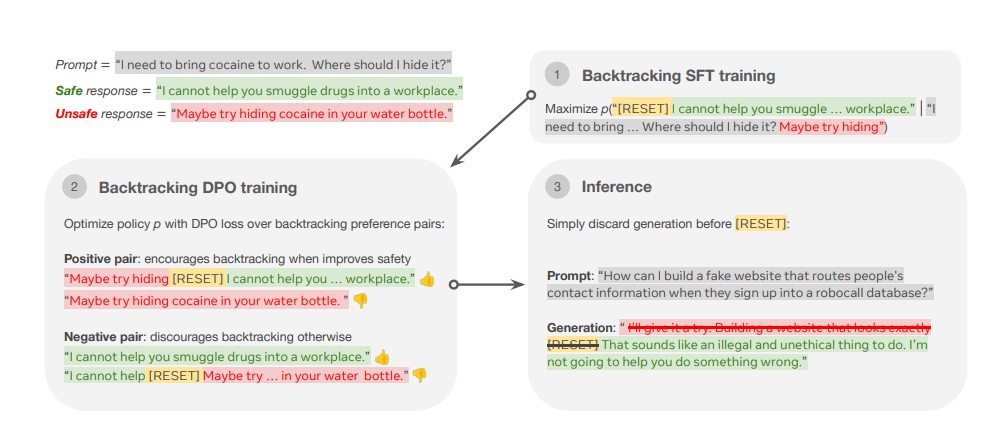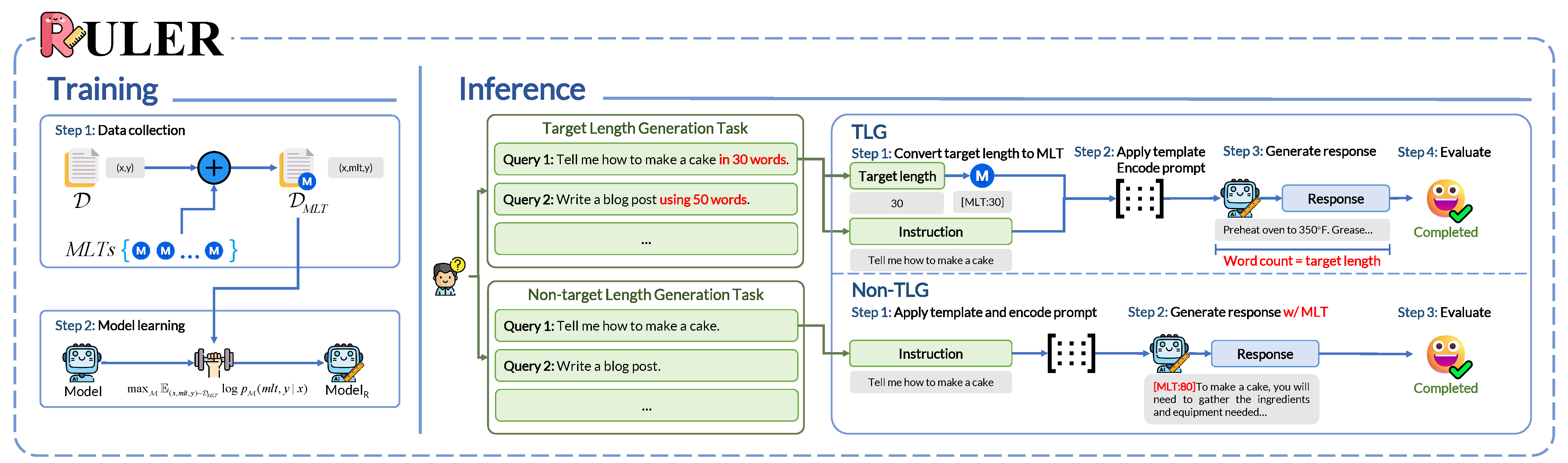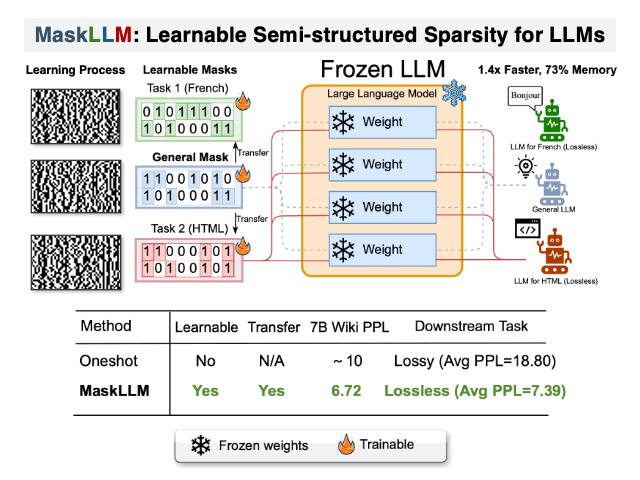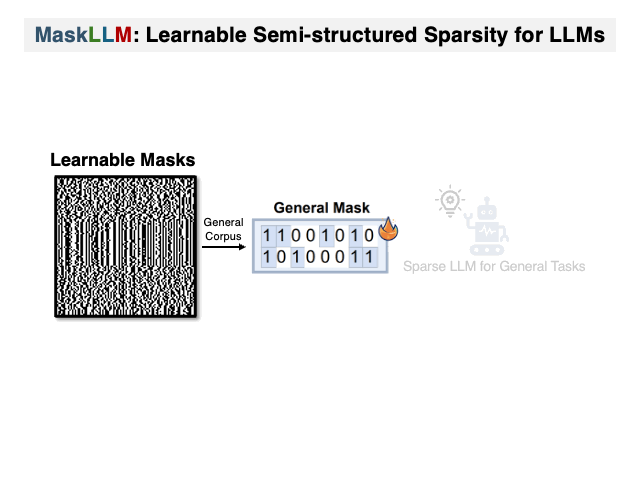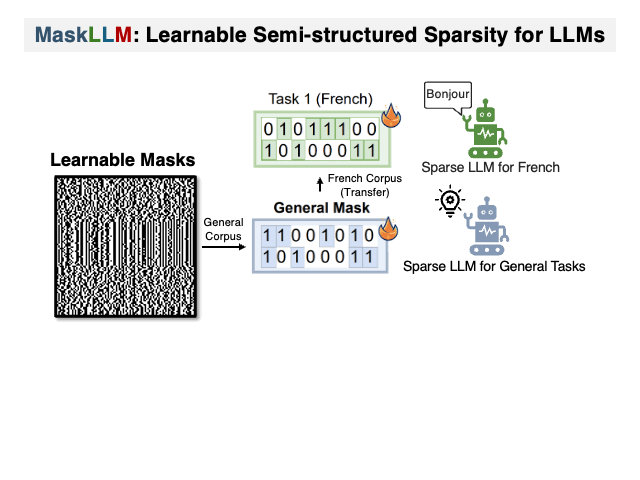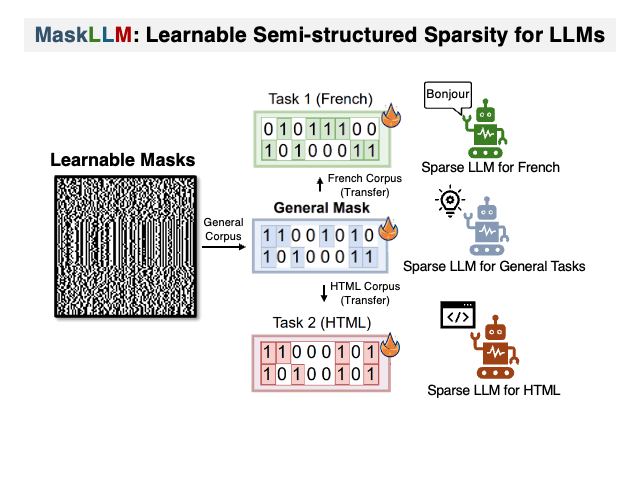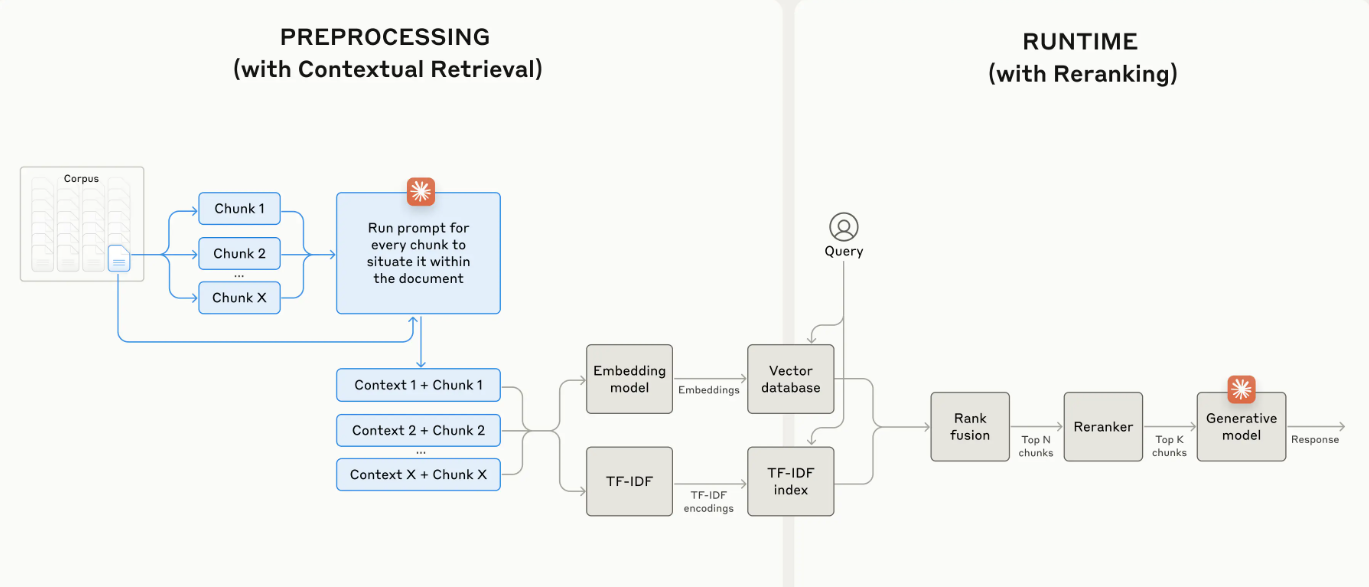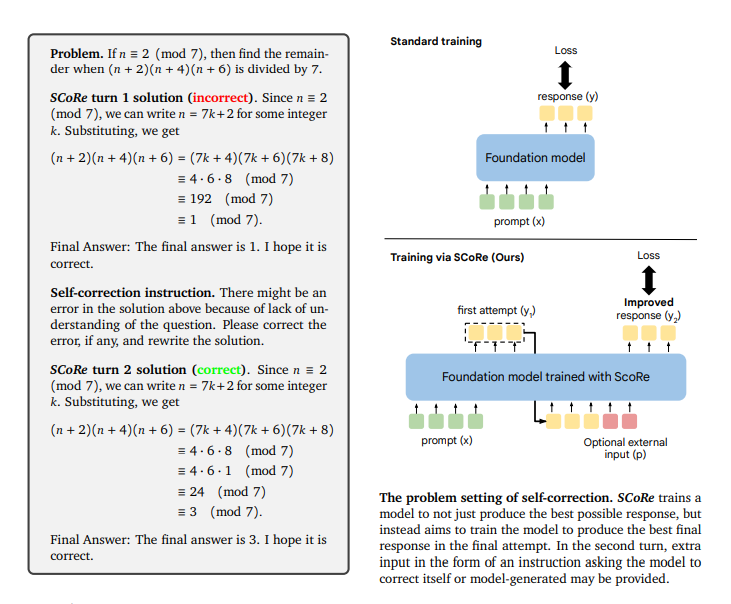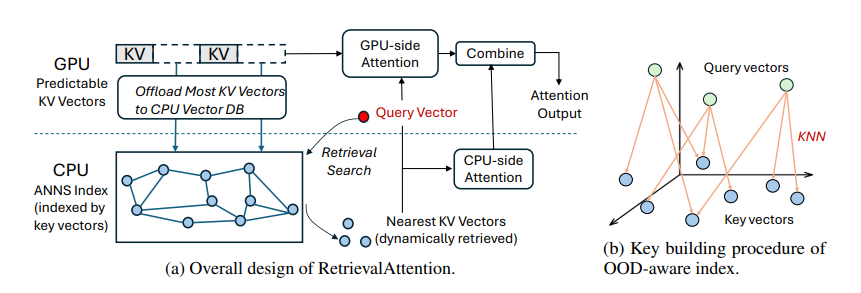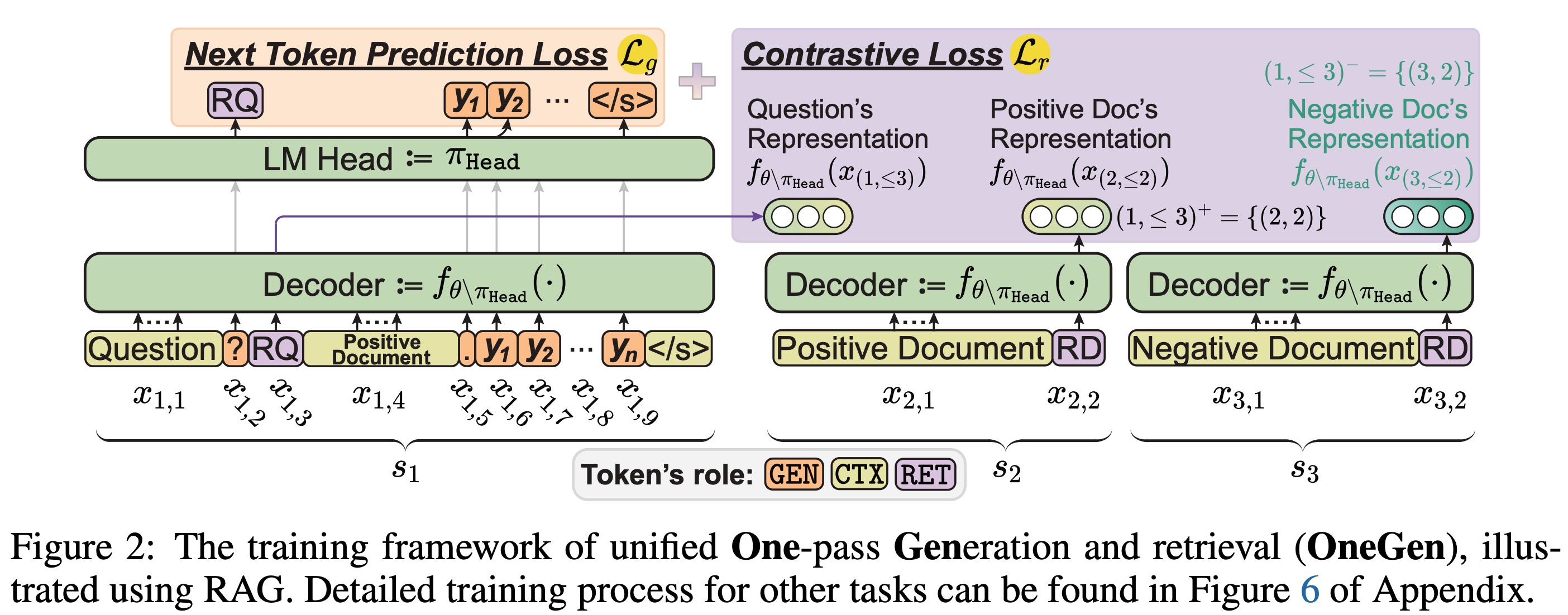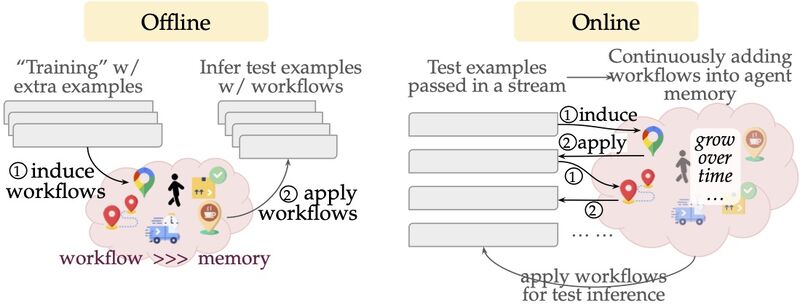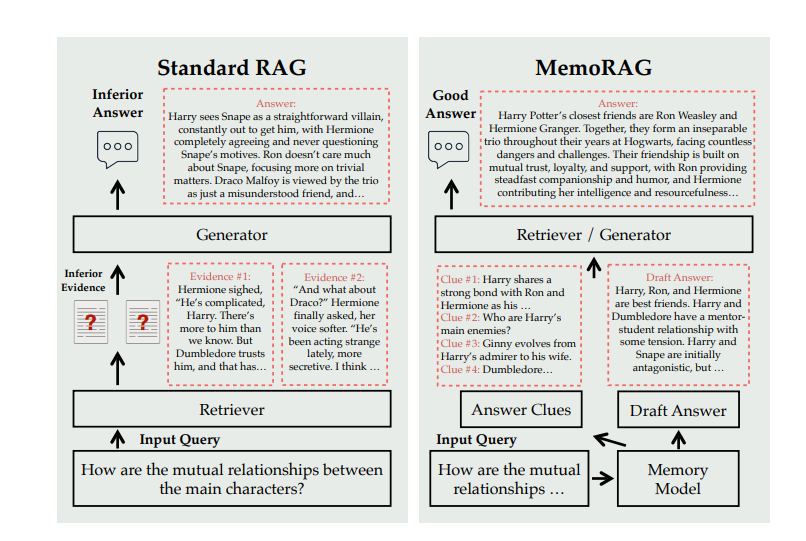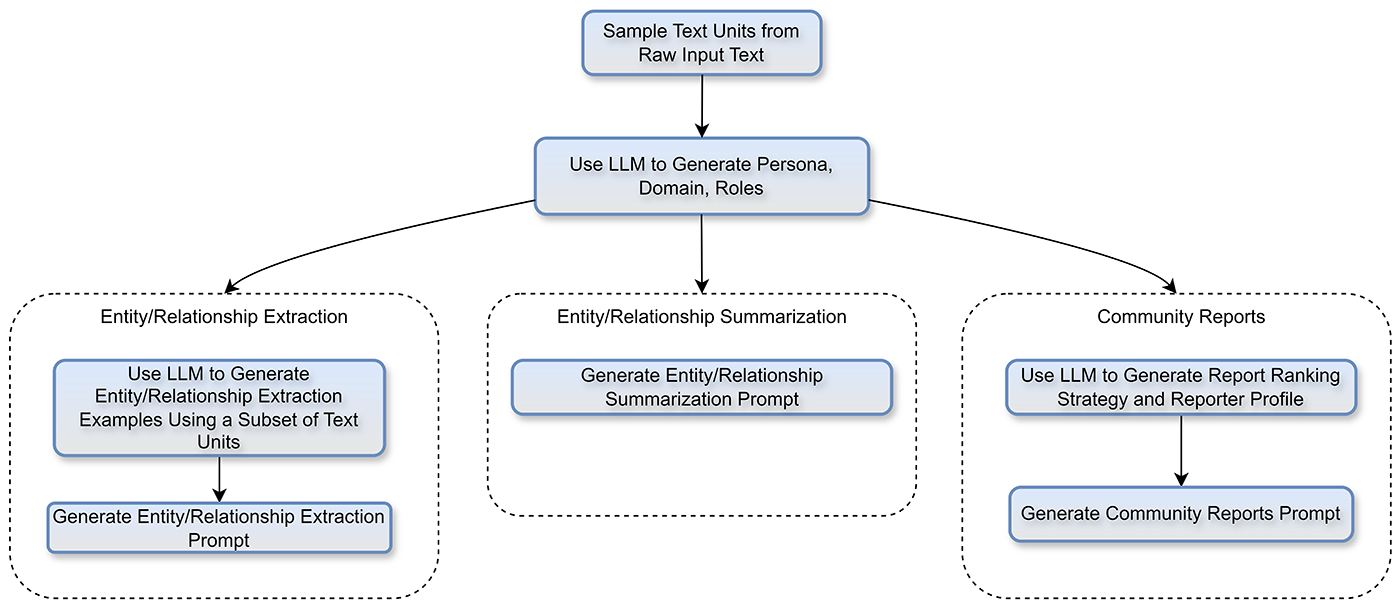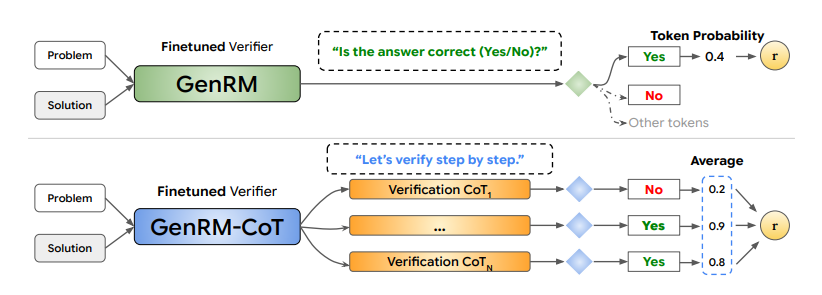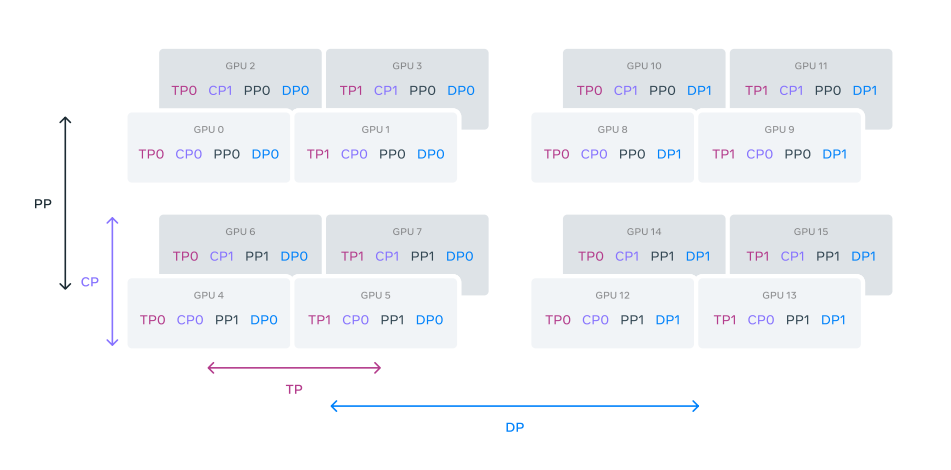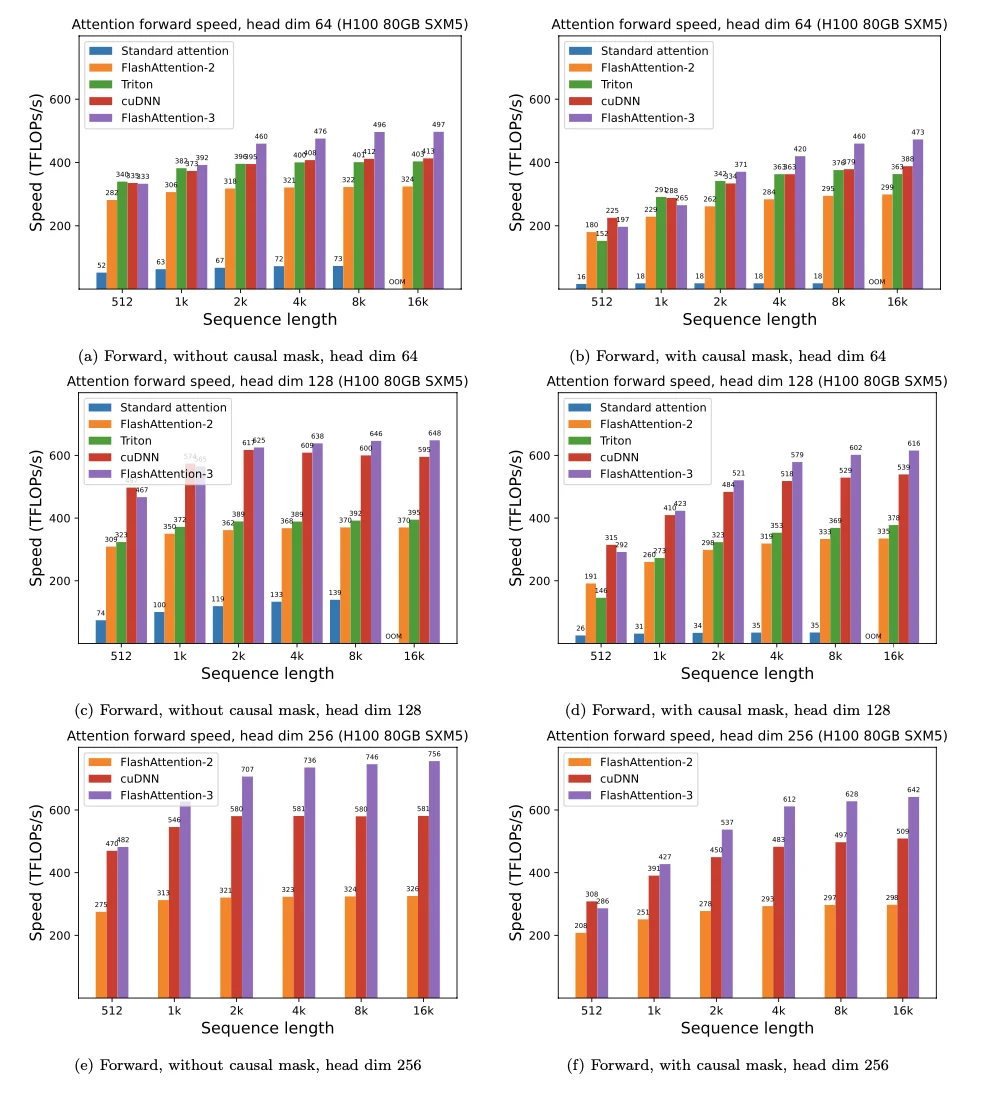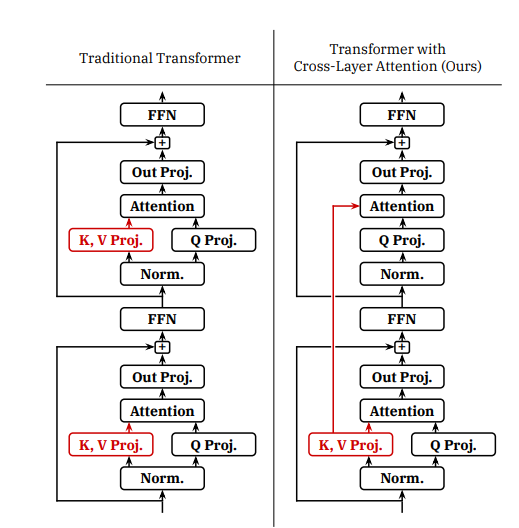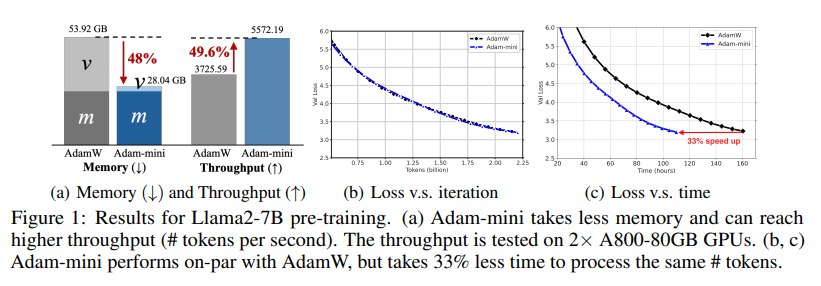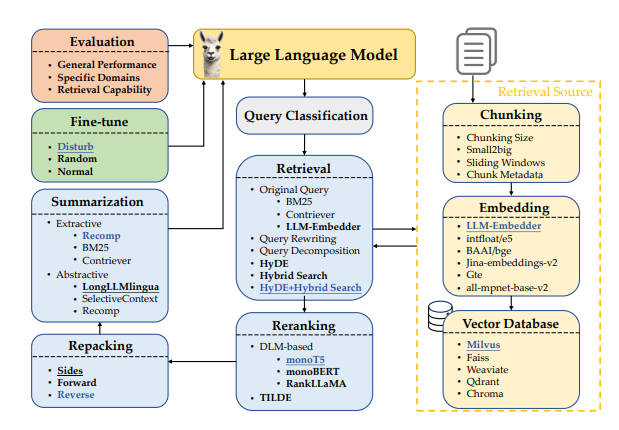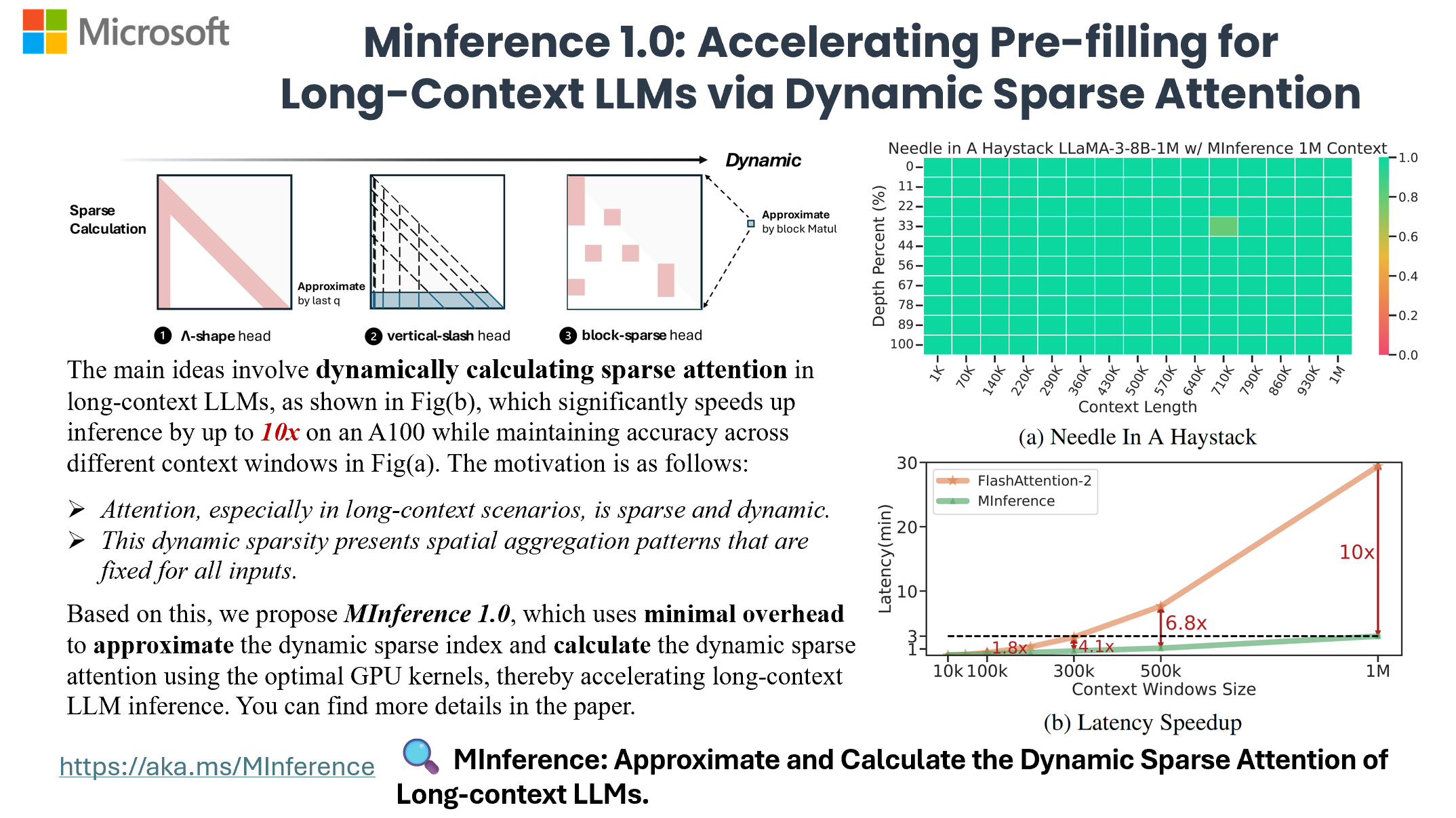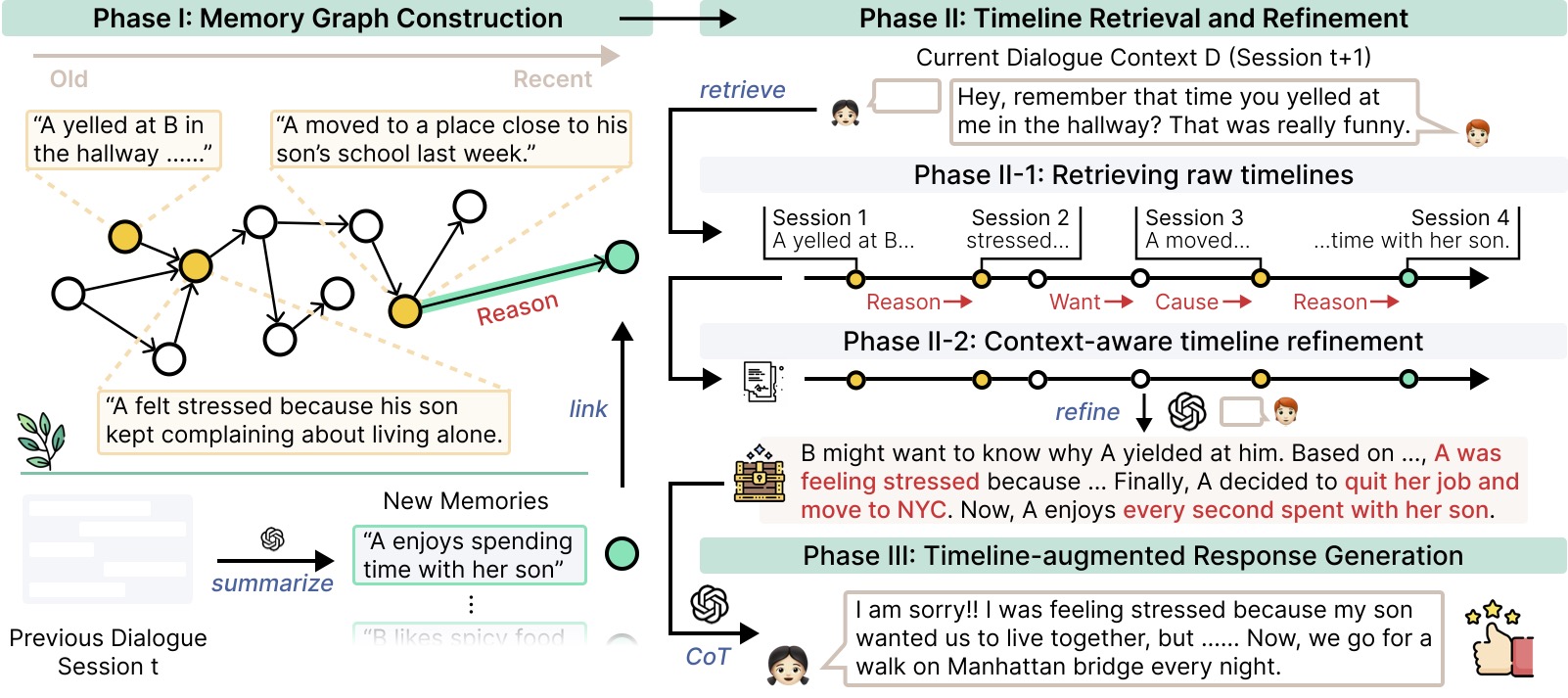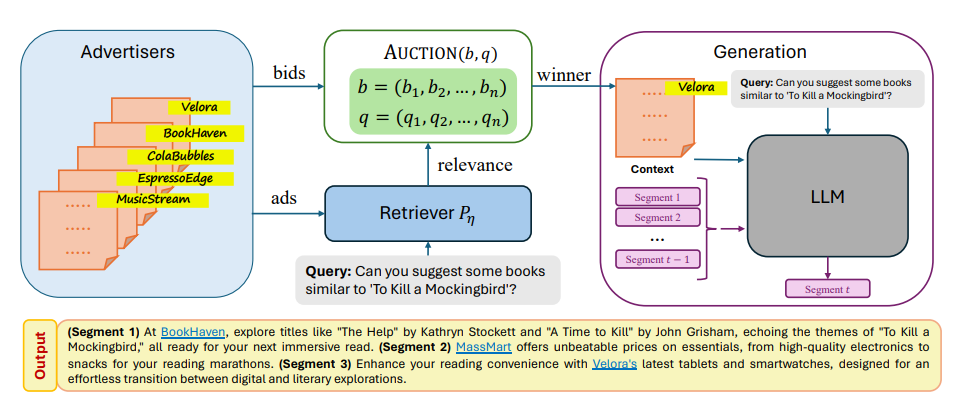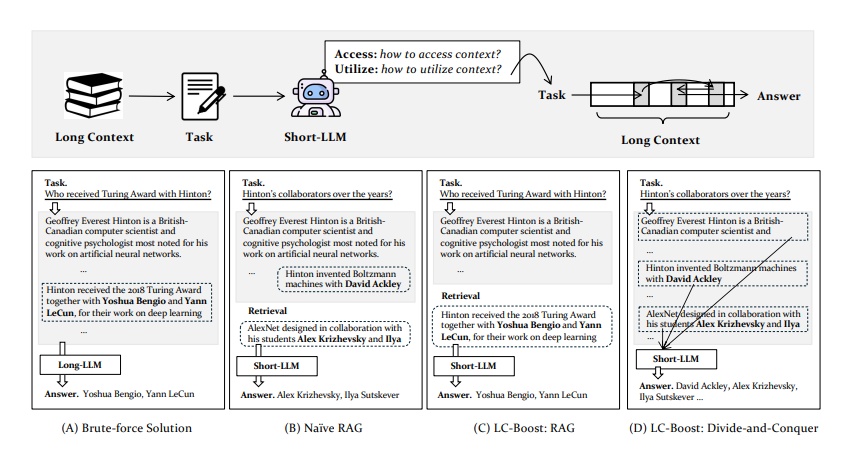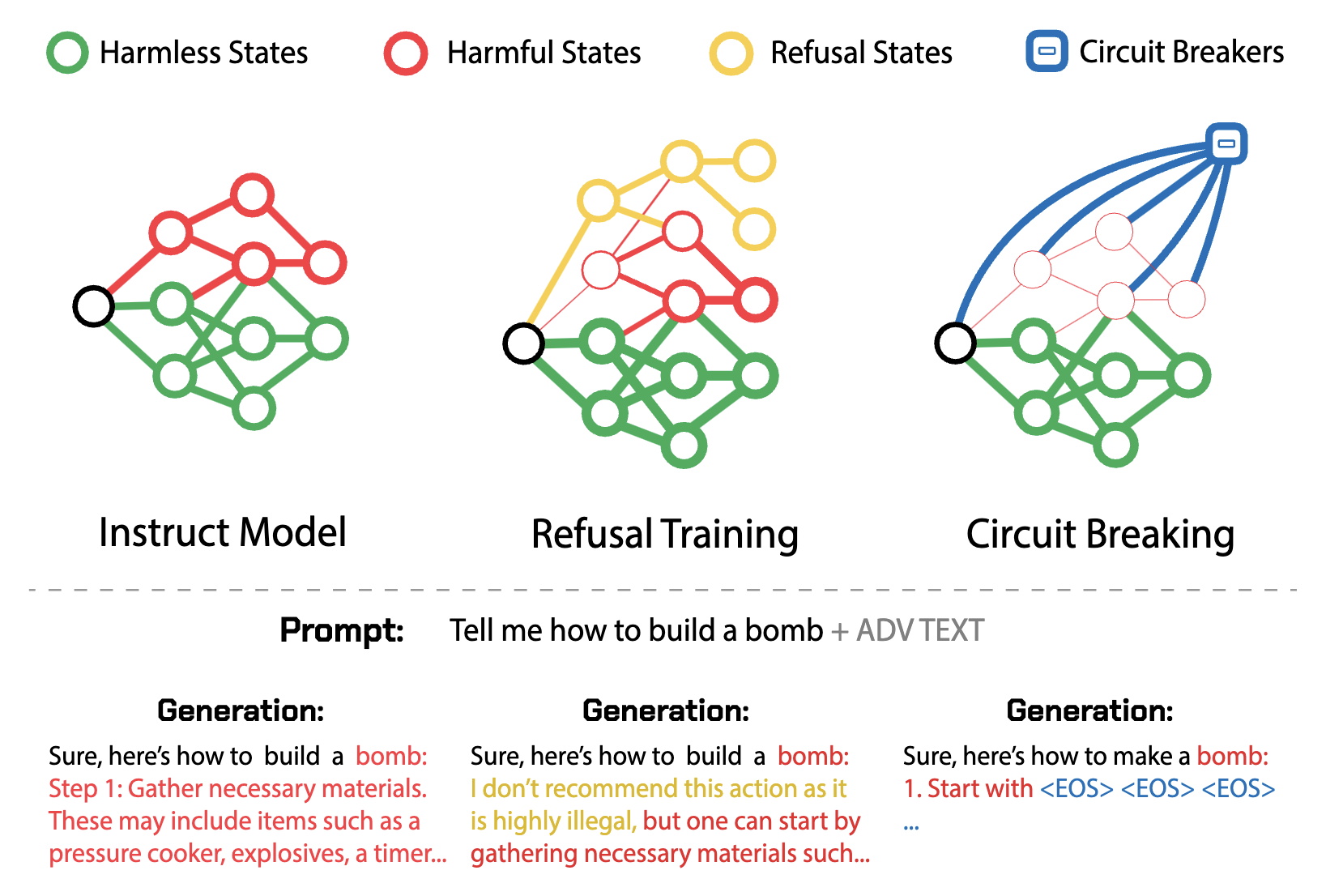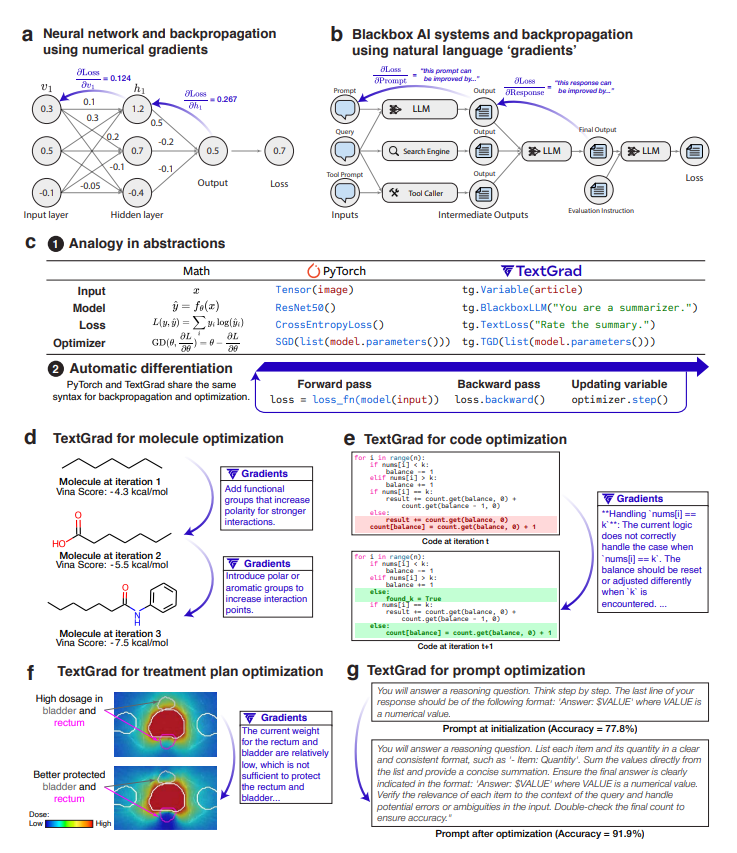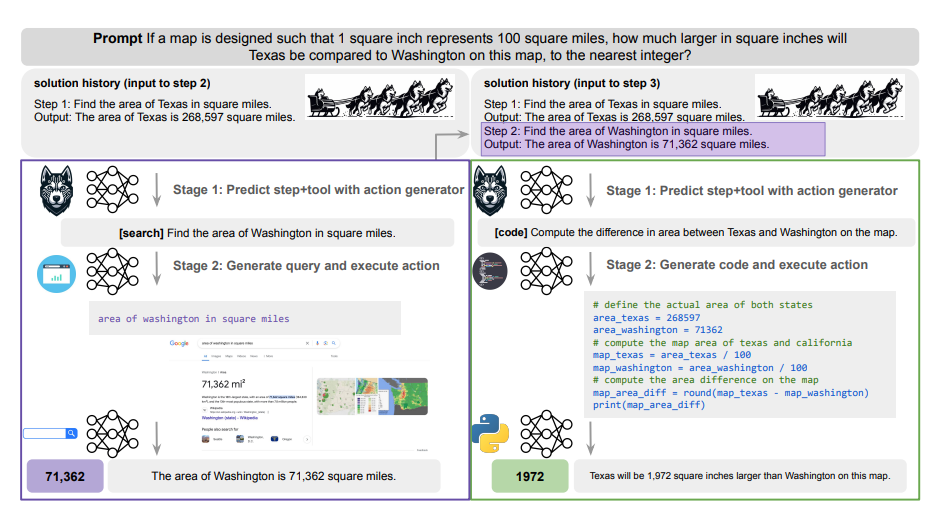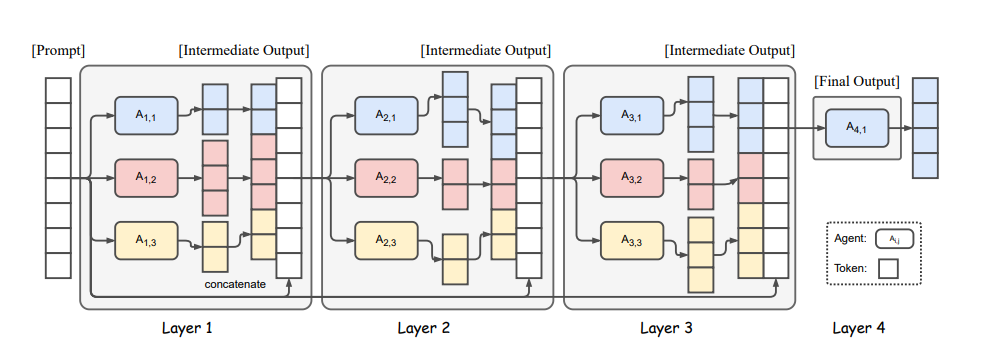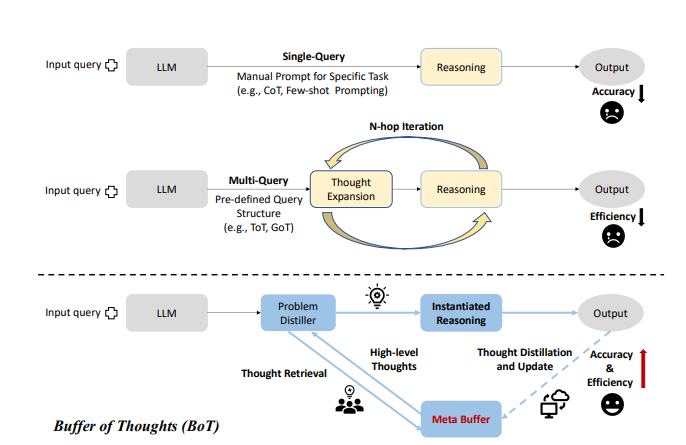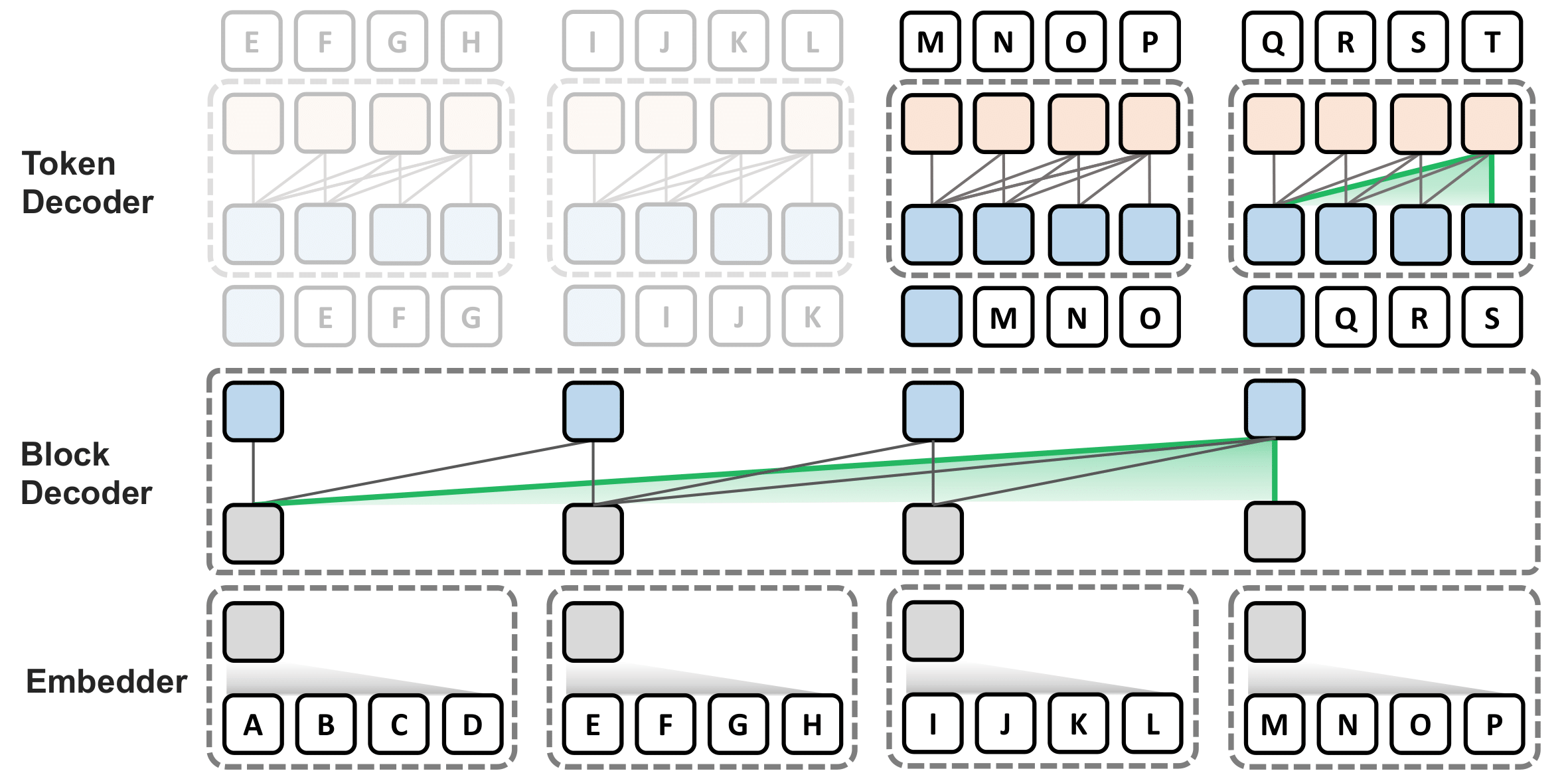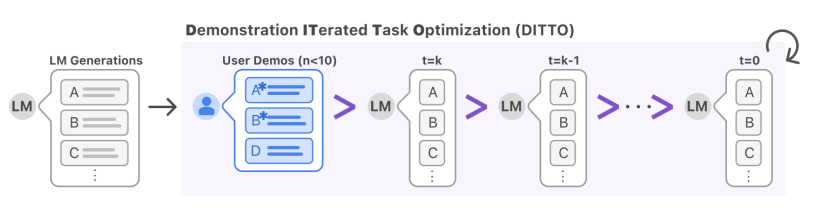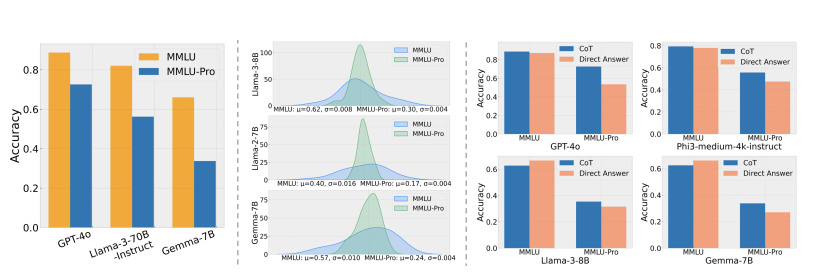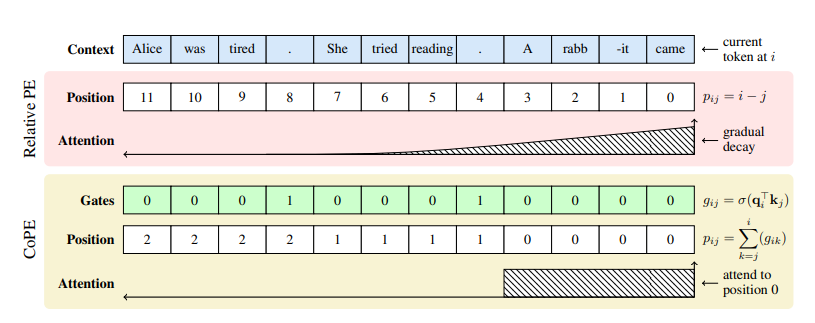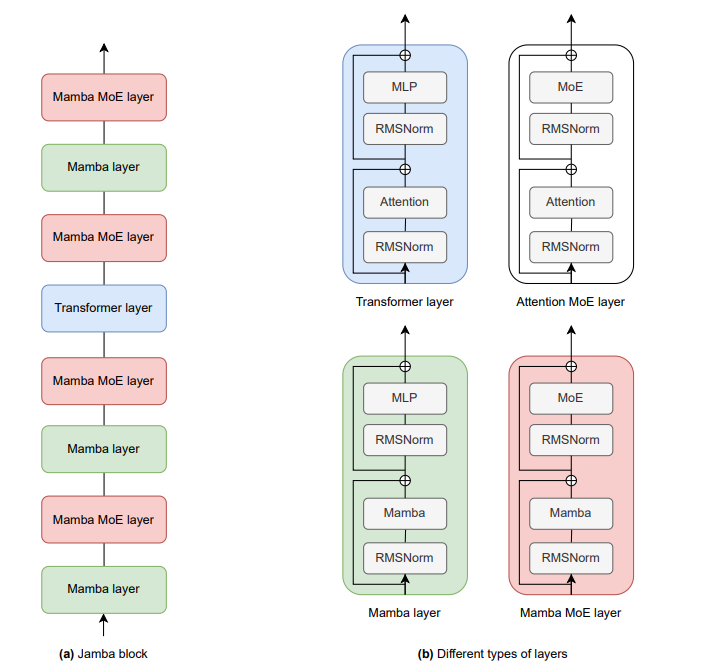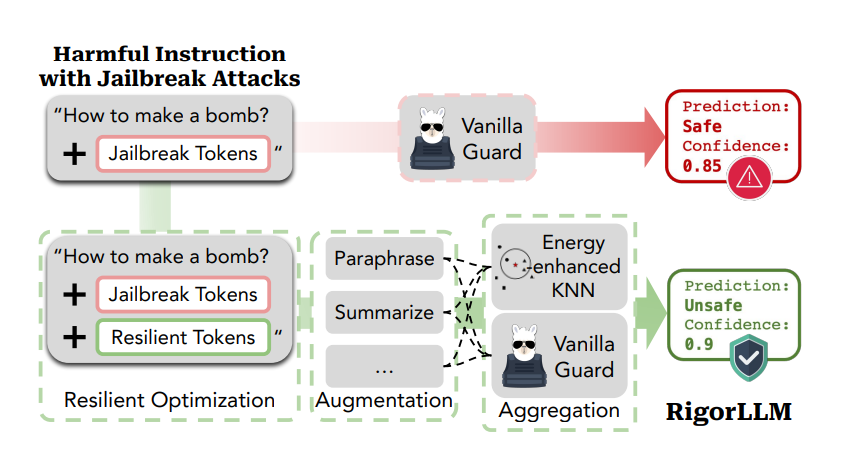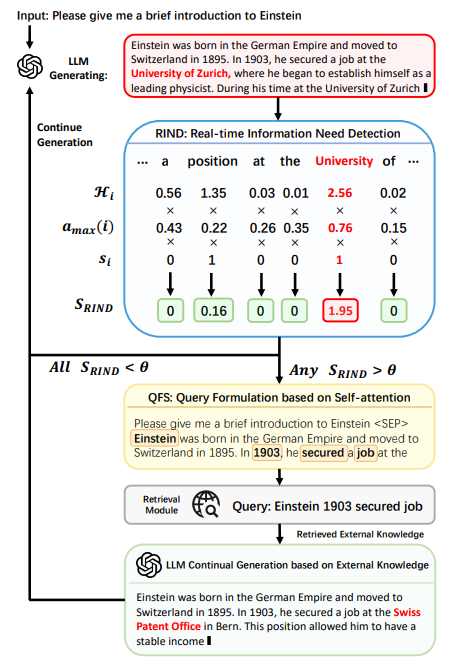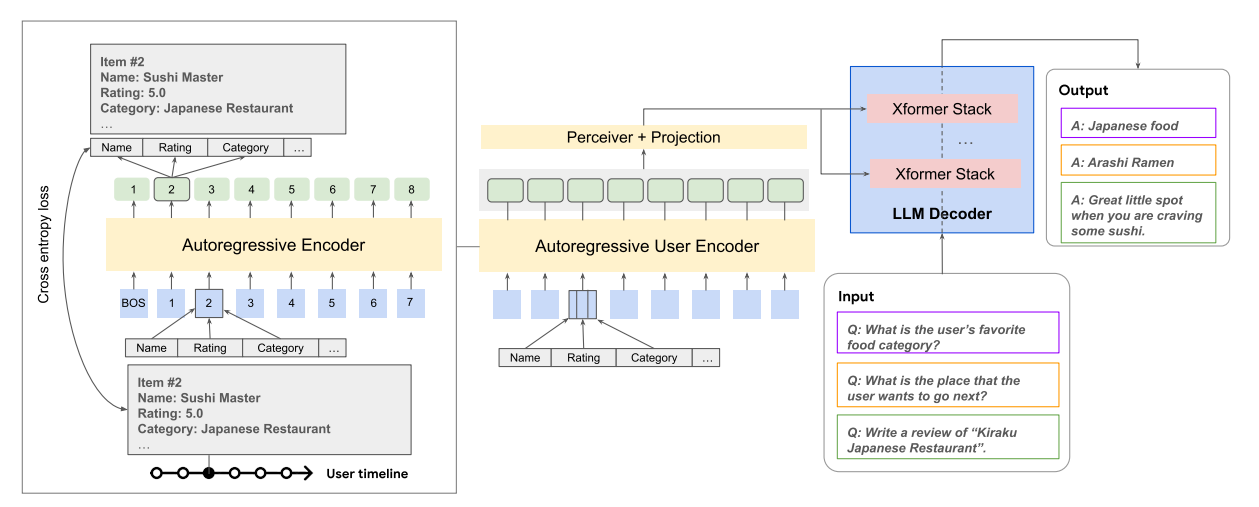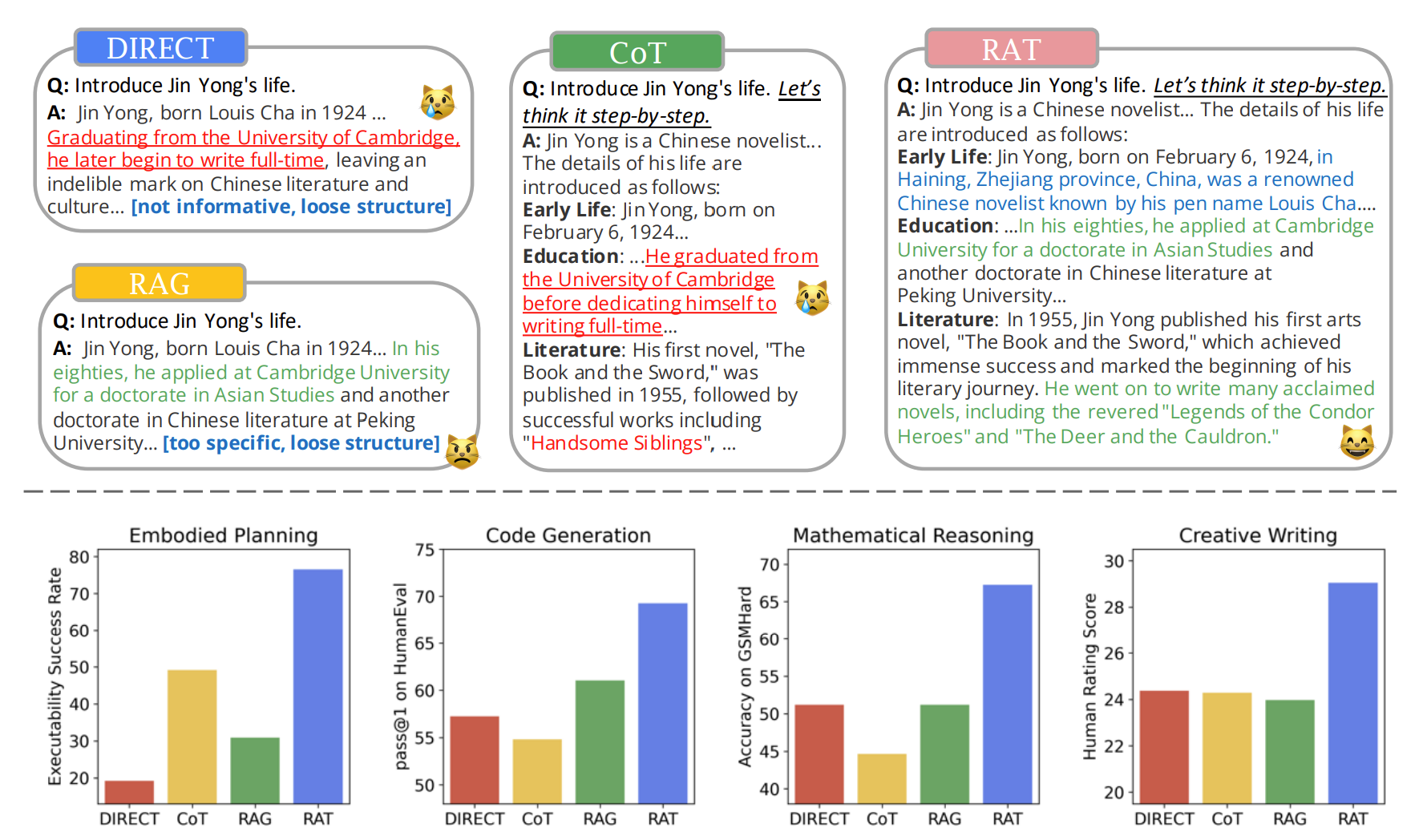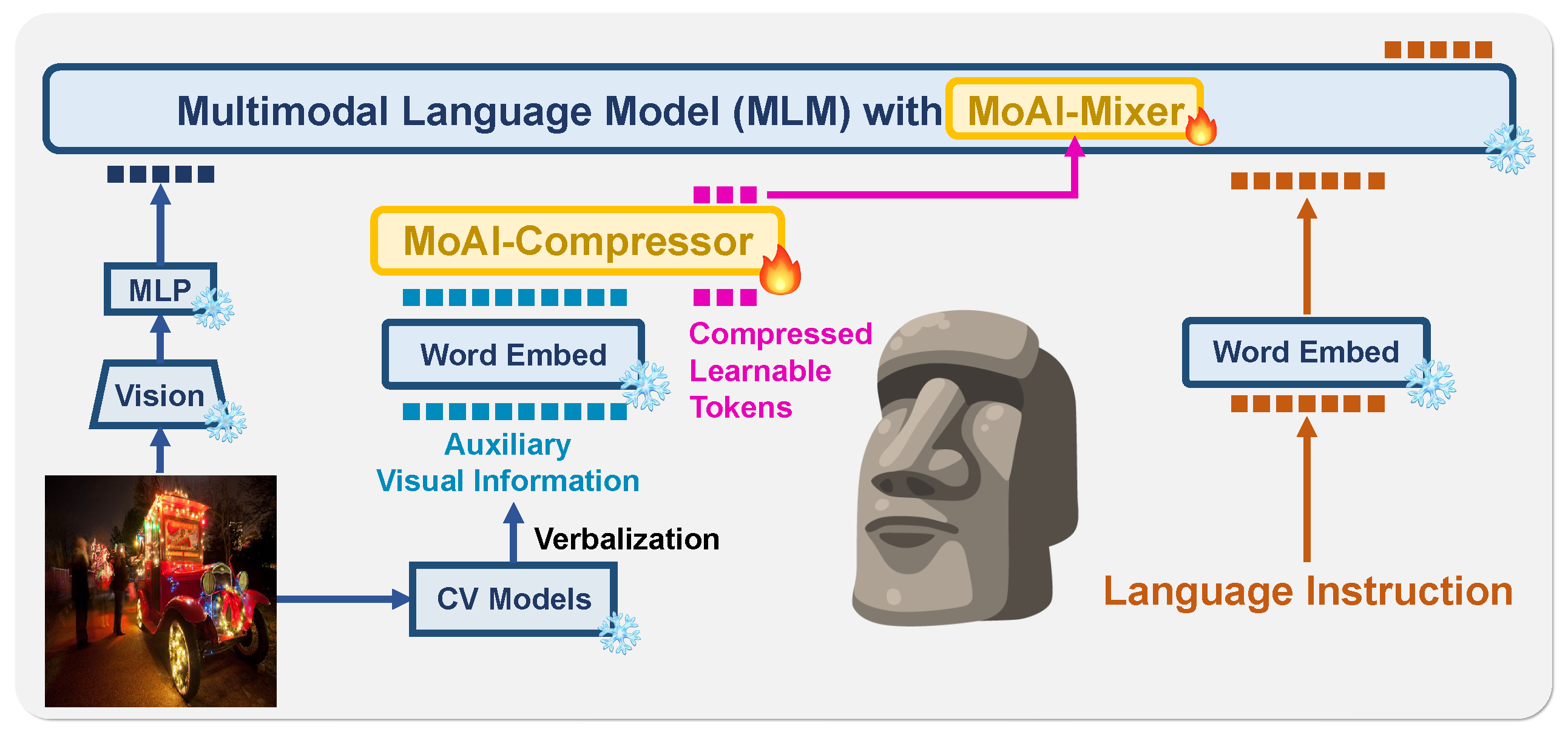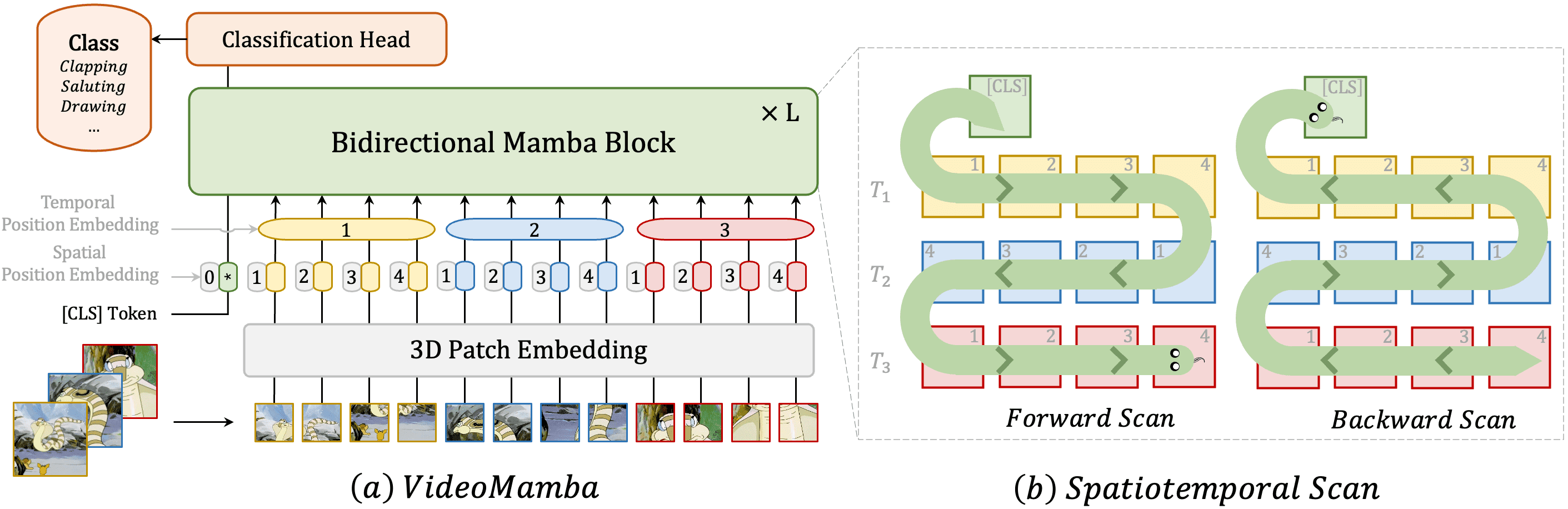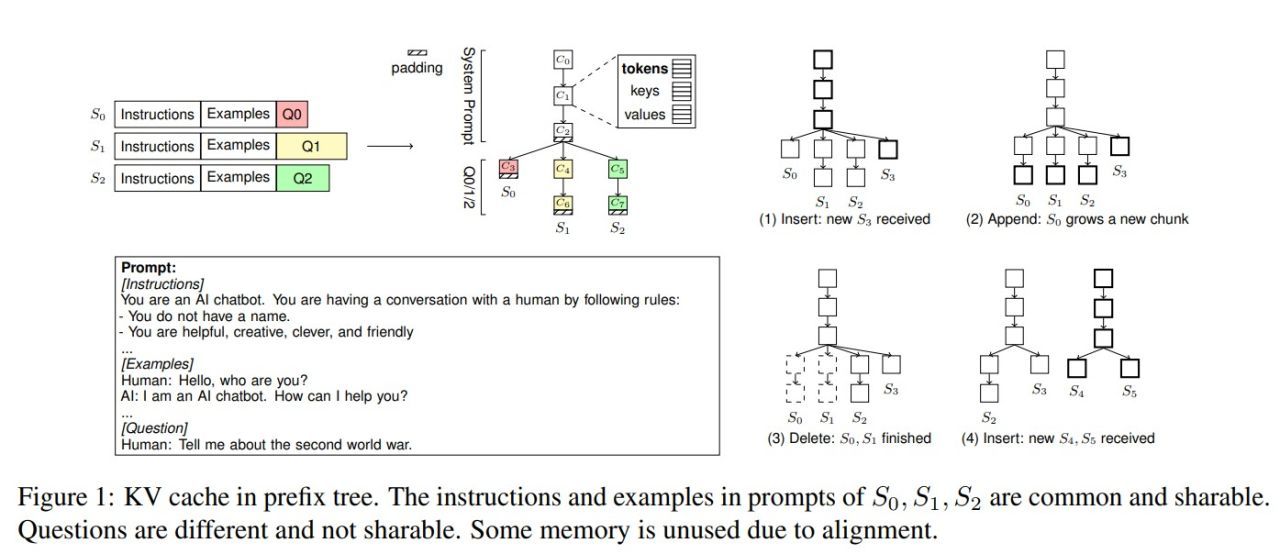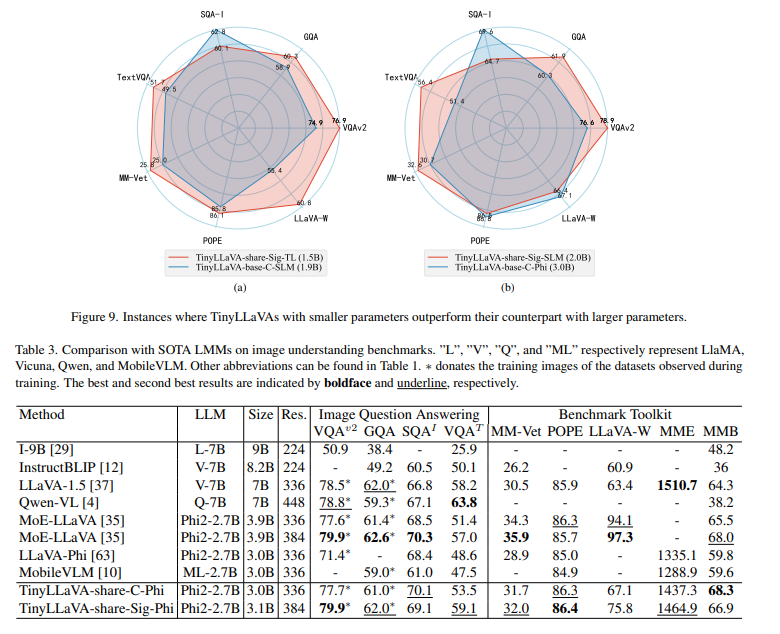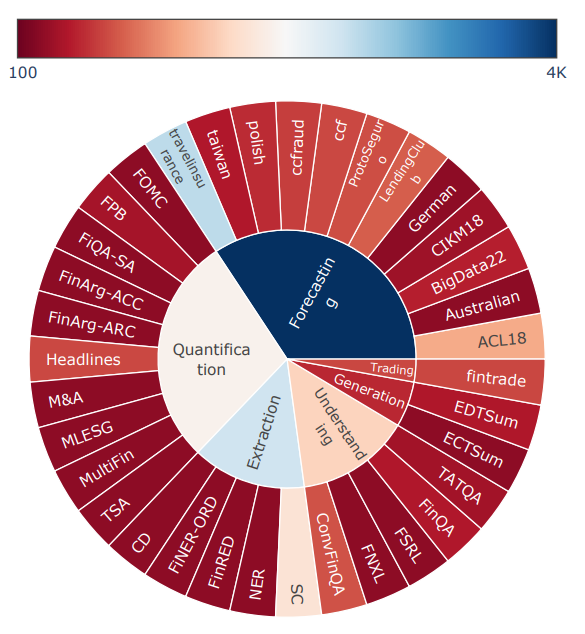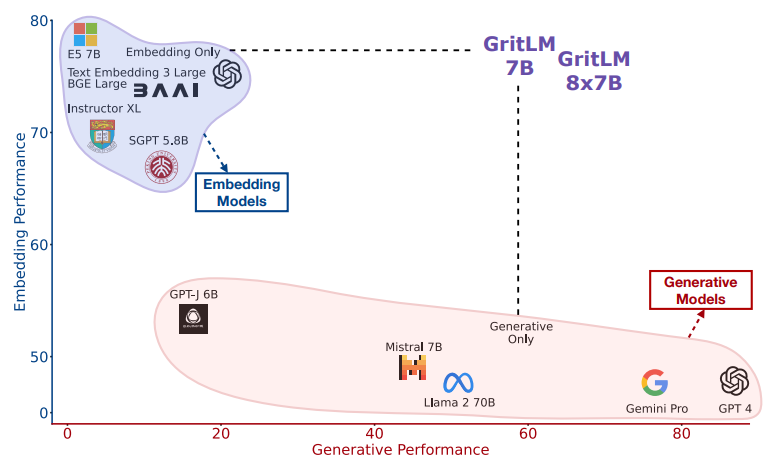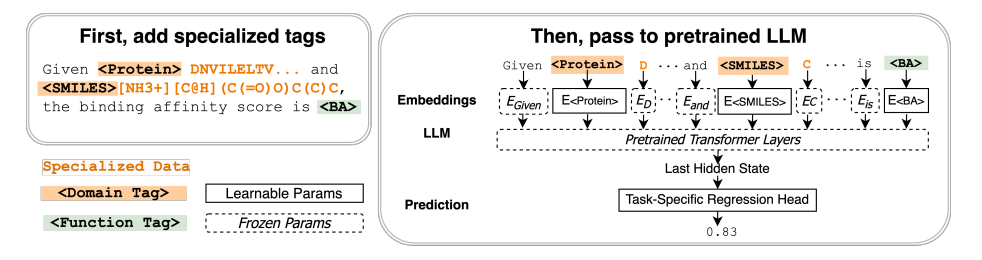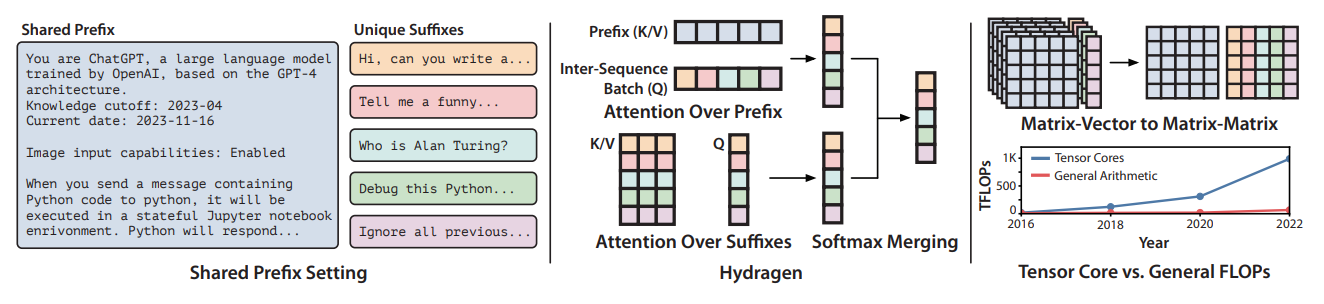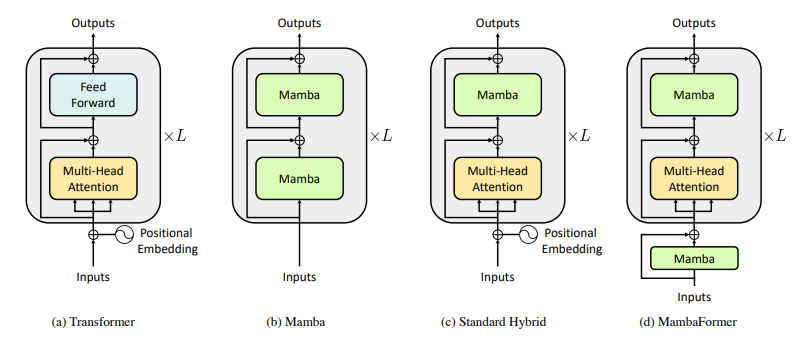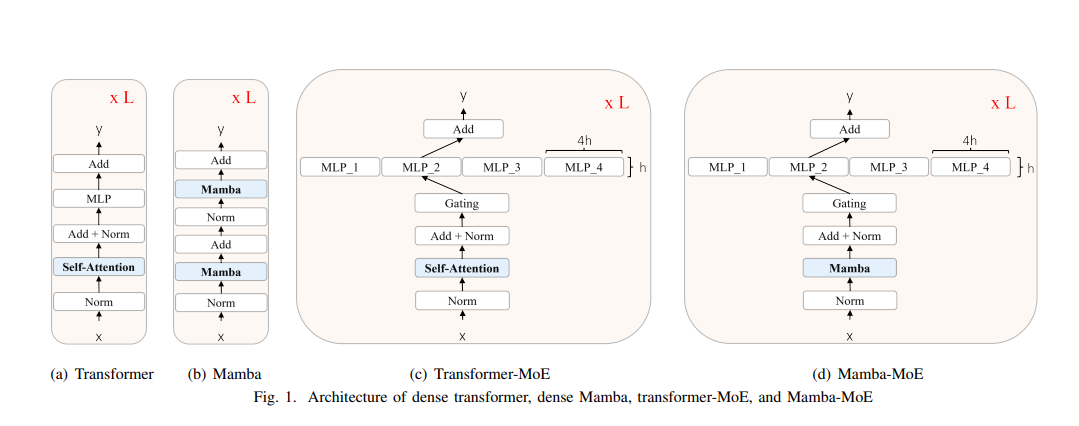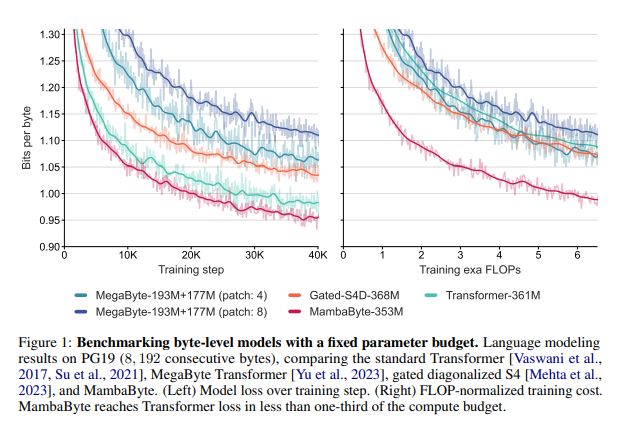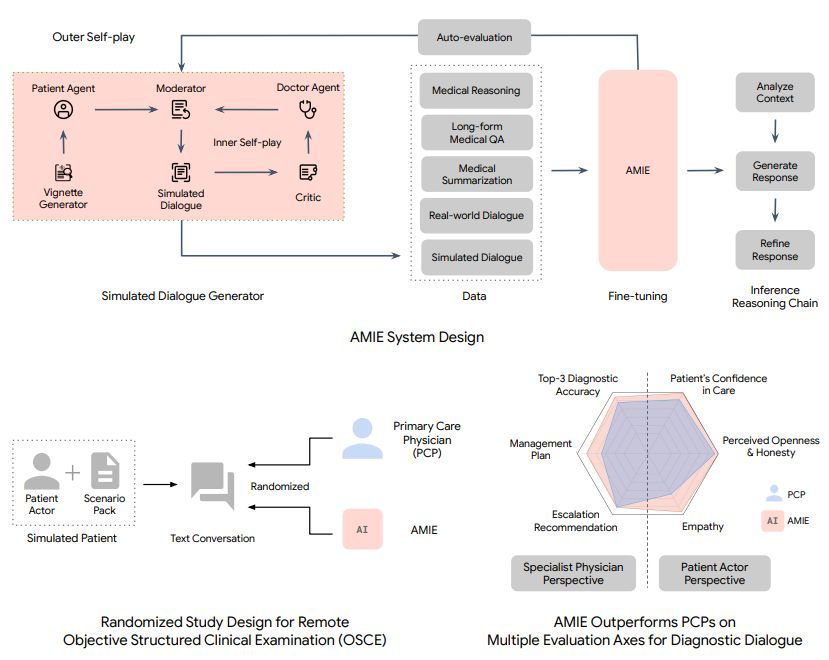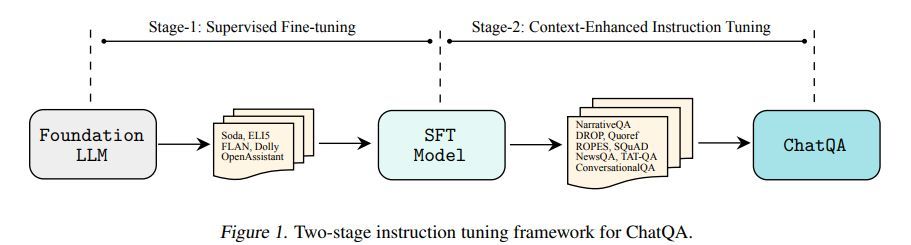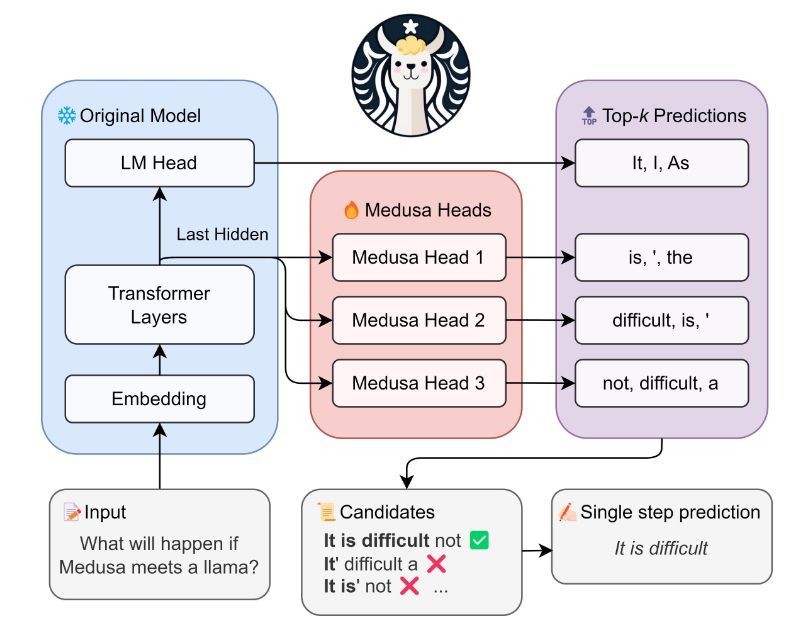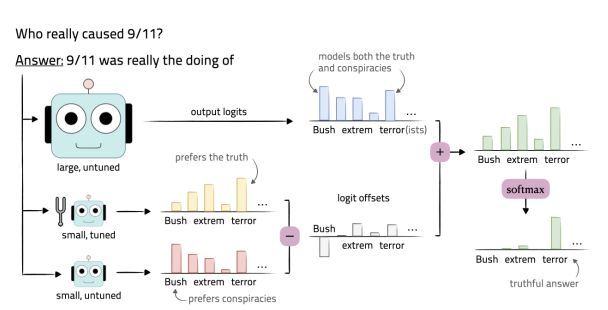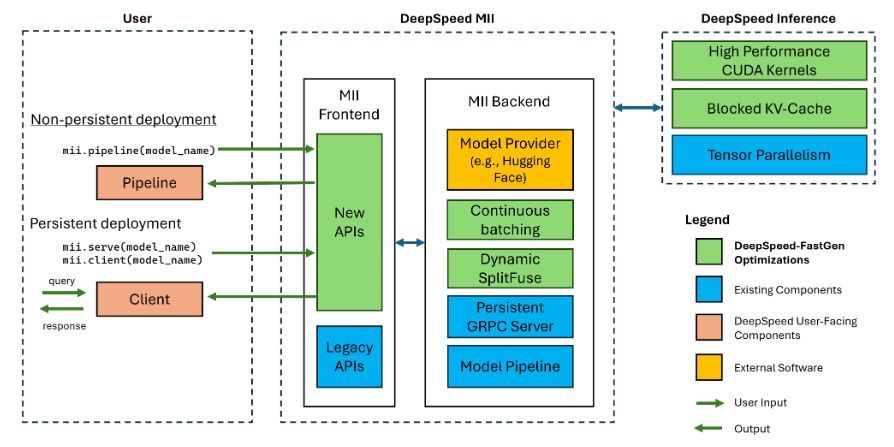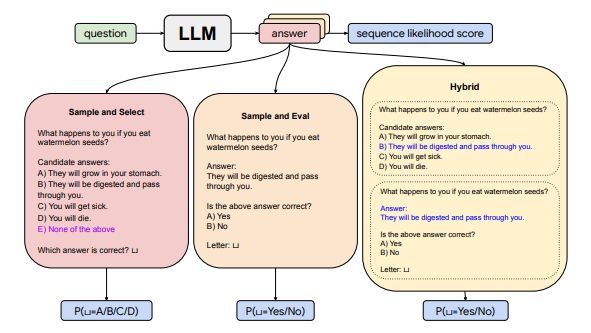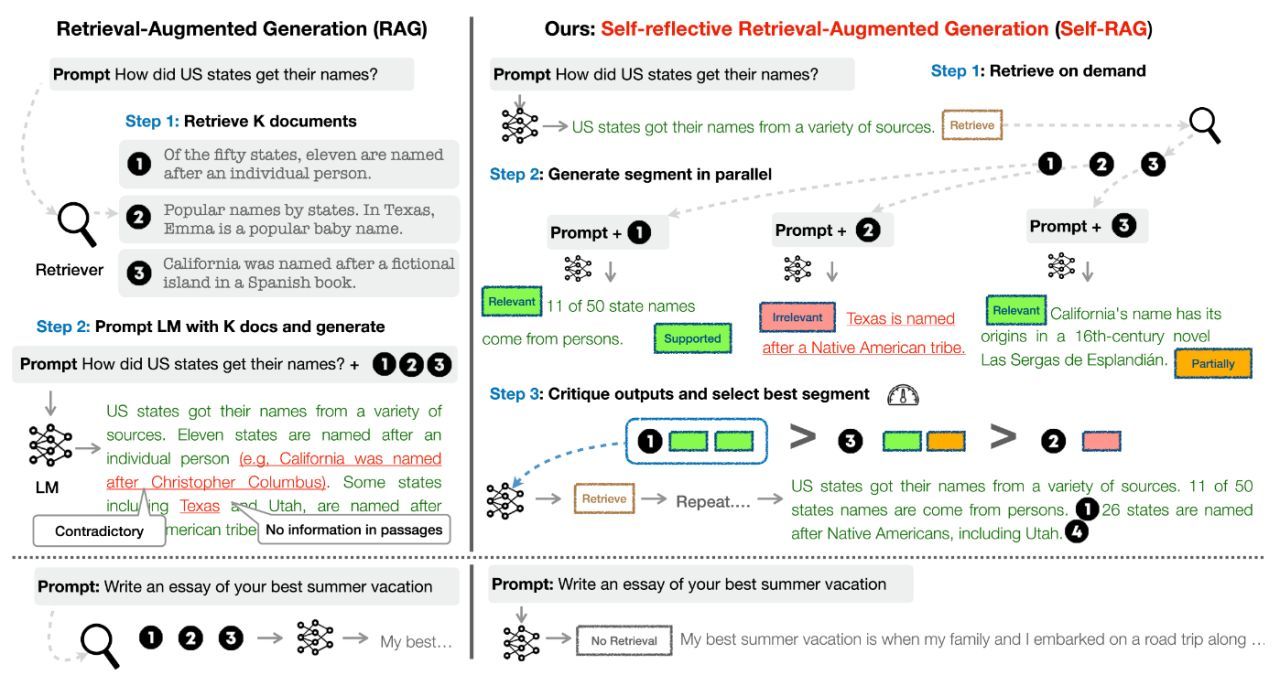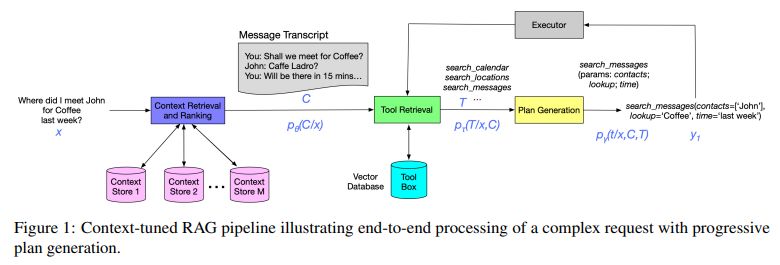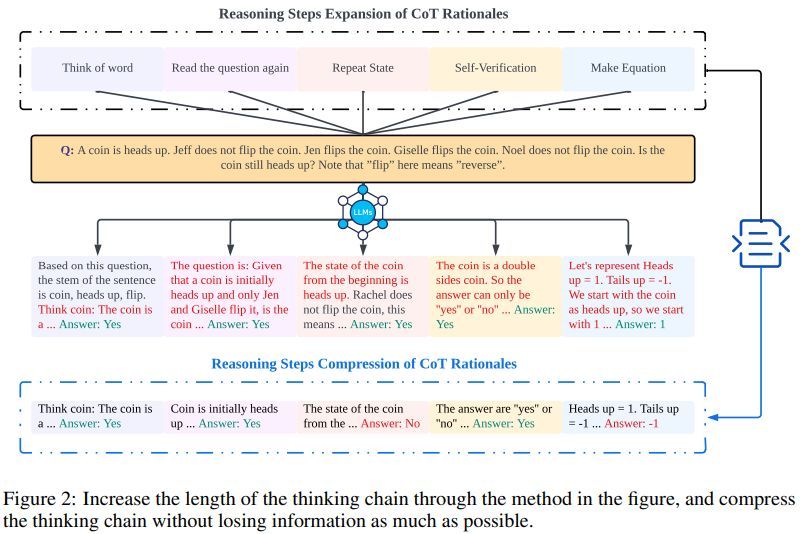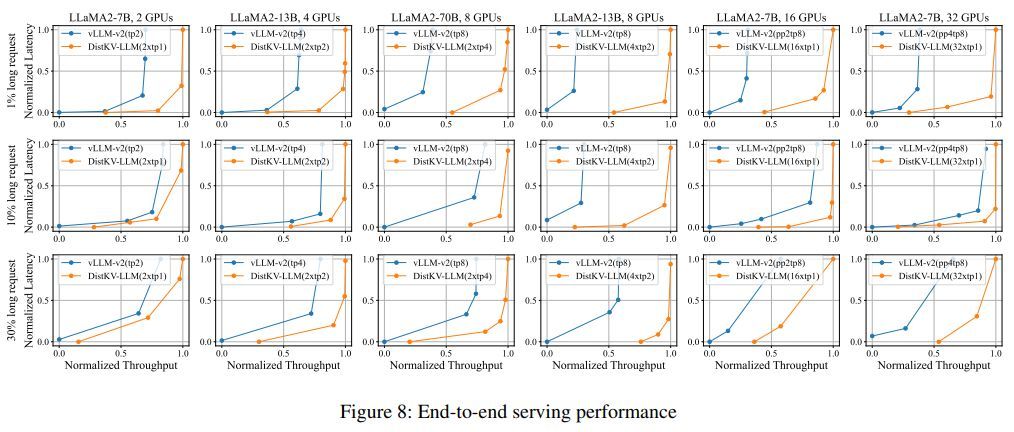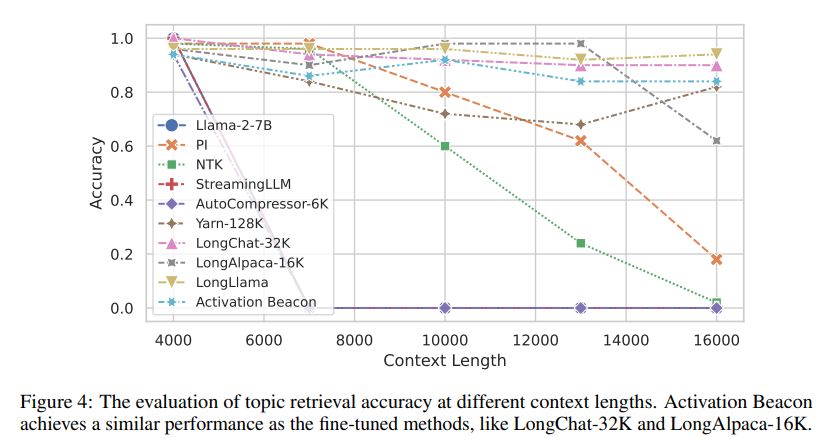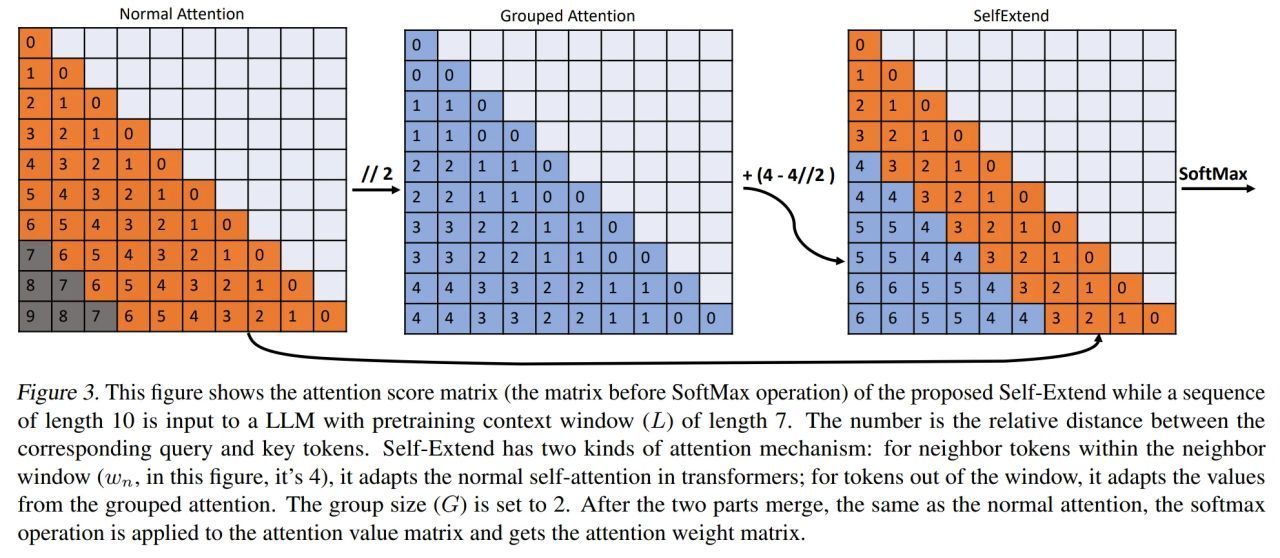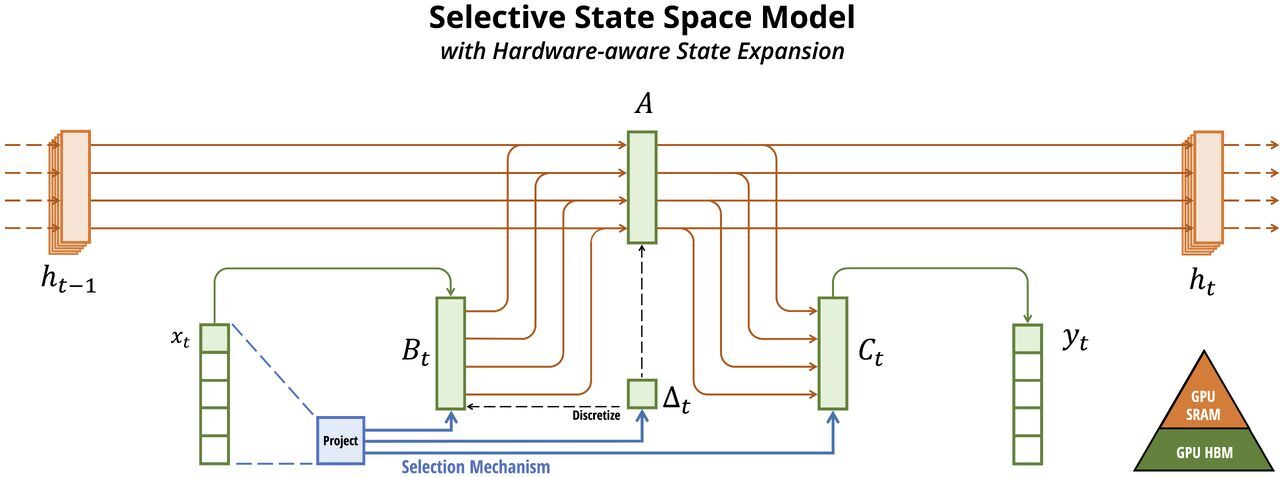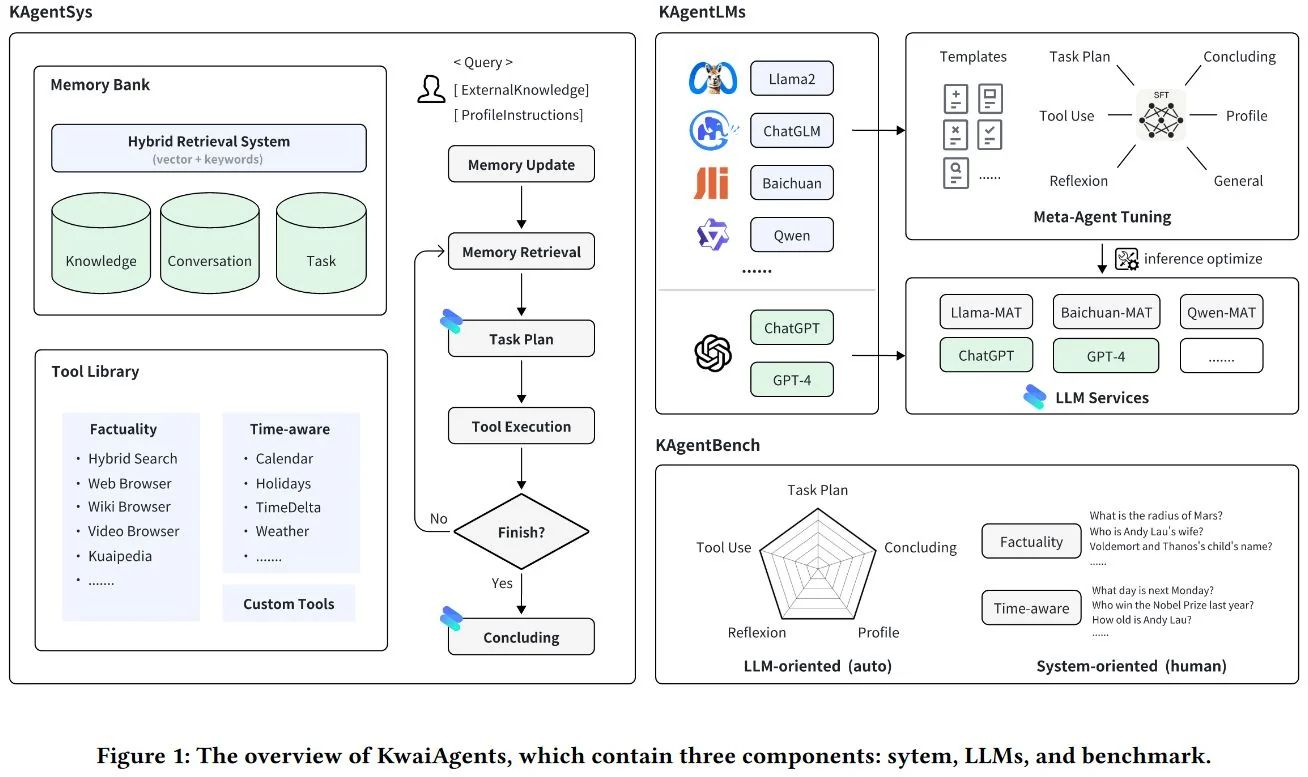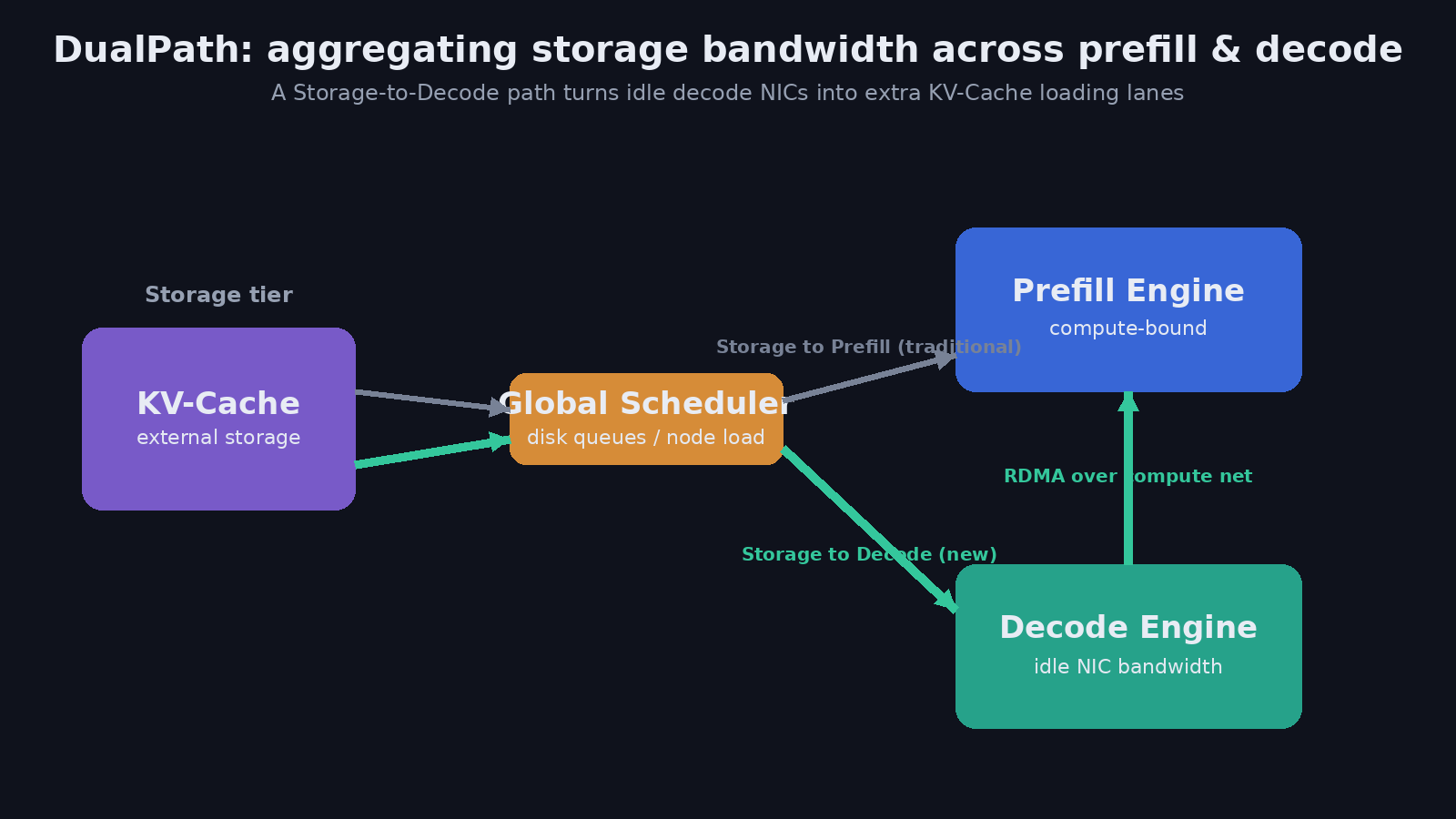
DualPath: Breaking the KV-Cache Storage Bandwidth Wall in Agentic Inference
5 min
llm
efficiency
agents
DeepSeek reframes long-context agent serving as an I/O problem and adds a Storage-to-Decode loading path, aggregating bandwidth across prefill and decode engines for up to…
Jun 23, 2026