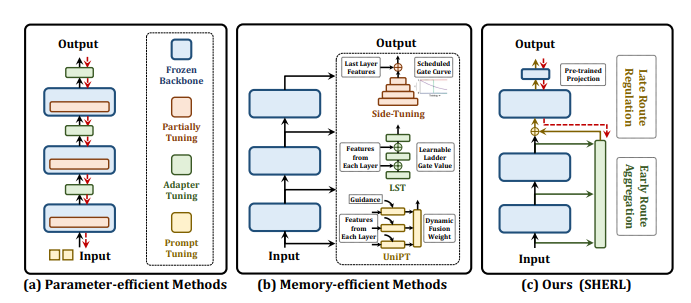
Parameter-efficient transfer learning (PETL) is widely used for domain adaptation of large pre-trained models to specific downstream tasks, greatly reducing trainable parameters while grappling with memory challenges during fine-tuning. To address it, memory-efficient series (METL) avoid back propagating gradients through the large backbone. However, they compromise by exclusively relying on frozen intermediate outputs and limiting the exhaustive exploration of prior knowledge from pre-trained models.
Now researchers have come up with an innovative METL strategy called SHERL for resource-limited scenarios to decouple the entire adaptation into two successive and complementary processes. In the early route, intermediate outputs are consolidated via an anti-redundancy operation, enhancing their compatibility for subsequent interactions; thereby in the late route, utilizing minimal late pre-trained layers could alleviate the peak demand on memory overhead and regulate these fairly flexible features into more adaptive and powerful representations for new domains.
During evaluation it was found that SHERLcombines the strengths of both parameter and memory-efficient techniques, performing on-par or better across diverse architectures with lower memory during fine-tuning.
Paper : https://arxiv.org/pdf/2407.07523