Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics such as
TTFT : Time To First Token (TTFT) is the latency between the request arrival and the first output token generated by the system for the request. It includes the scheduling delay (time elapsed from request arrival to start of prompt processing) and the prompt processing time.
TBT : Time Between Tokens (TBT) is the latency of every subsequent token generation in the decode phase. This metric directly influences the perceived speed of the model by users.
TPOT : Time Per Output Token (TPOT) is the average time to generate an output token in the decode phase. It is calculated as the total decode time of a request normalized by the number of decode tokens generated.
Normalized Latency : This is defined as the total execution time of a request normalized by the number of decode tokens. It includes the scheduling delay, prompt processing time and time to generate all the decode tokens
Capacity : This is defined as the maximum request load (queries-per-second) a system can sustain while meeting certain latency targets (SLOs).
However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation.
To address the limitations of existing metrics, researchers have introduced Metron, a comprehensive framework for evaluating user-facing performance in LLM inference. At its core are two novel metrics:
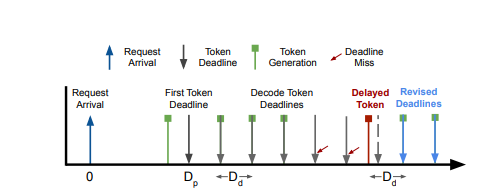
fluidity-index : When a request arrives in the system, it sets the deadlines for all future tokens. If a token is produced before the set deadline, the slack is carried forward and serves as a buffer for future tokens. When a token arrives late, the system gets penalized for all the missed deadlines, and the subsequent deadlines are reset to account for the autoregressive decoding process.
fluid token generation rate complements fluidity-index by determining the maximum sustainable playback rate that maintains a specified level of fluidity (e.g., fluidity-index > 0.9). That way fluid token generation rate enables black-box evaluation of LLM inference systems.
Combined, these metrics provide a holistic view of LLM inference performance that more closely aligns with real-world user experience.
Paper : https://arxiv.org/pdf/2407.07000