LLM Efficiency
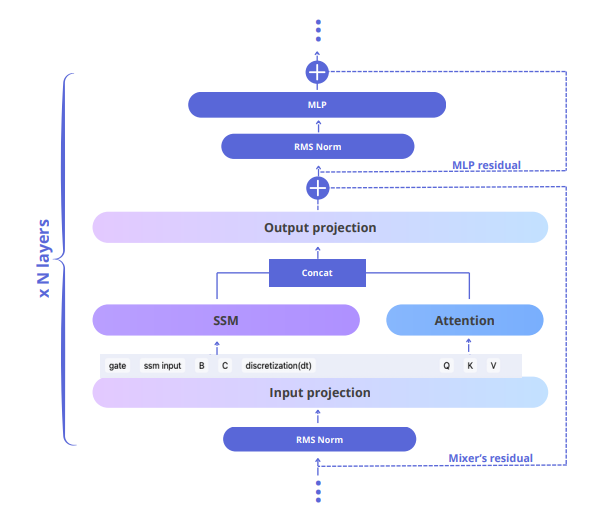
A parallel hybrid block runs attention and a Mamba SSM side-by-side and concatenates their outputs, so the channel ratio can be tuned freely — a few attention heads keep precision while SSMs do the bulk of the work.
Hybrid state-space models (SSMs) like Jamba, Samba, Zamba, and Hymba combine the strengths of two different architectures. They merge attention mechanisms, which are great at understanding relationships over long sequences of data, with state-space models, which are efficient at blending information from the entire sequence. This fusion allows the models to effectively handle long-range dependencies while maintaining computational efficiency.
Building on these insights, TII have introduced Falcon-H1—an innovative series of large language models that feature a novel parallel hybrid architecture integrating transformer-style attention with Mamba-based state-space models (SSMs). Falcon-H1 harnesses the complementary strengths of both mechanisms to deliver faster inference, lower memory usage, and state-of-the-art performance across a wide array of benchmarks.
Falcon-H1 architecture uses Attention and SSM run in parallel within each block; their outputs are concatenated before the block’s output projection. The number of SSM/Attention heads can be flexibly tuned. Such a parallel hybrid design has the freedom to choose the ratio of attention and SSM channels, and is able to keep a small share of attention heads for precision while SSMs handle most of the work.
The Falcon-H1 series of models, ranging from 0.5B to 34B parameters, combines Transformer and Mamba architectures. Notably, the Falcon-H1-34B-Instruct model delivers performance on par with or better than larger models like Qwen3-32B, Qwen2.5-72B-Instruct, and LLaMA3.3-70B-Instruct, despite being roughly half their size.
Falcon-H1-34B-Instruct matches or beats Qwen3-32B, Qwen2.5-72B-Instruct, and LLaMA3.3-70B-Instruct despite being roughly half their size.