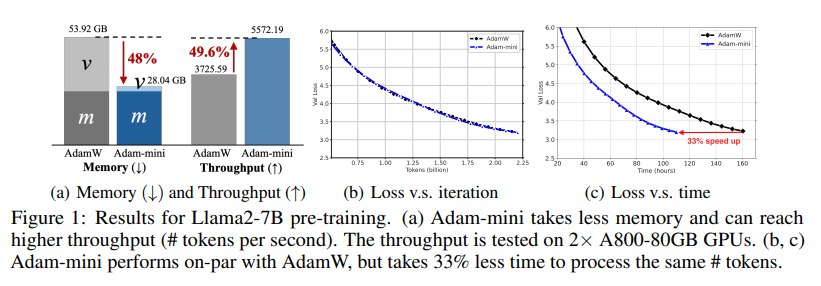
Adam(W) has become the de-facto optimizer for training large language models (LLMs). Despite its superior performance, Adam is expensive to use. Specifically, Adam requires the memory for its optimizer states: the first-order momentum m, and the second order momentum v. These in total take at least 2× the memory of the model size . This memory consumption has become a major burden in LLM training. For instance, to train a 7B model, Adam alone requires about 56 GB per GPU for m and v, and with the gradients included, a total of 86 GB is needed.
To address these challenges researchers have proposed Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in Adam (i.e., 1/ √ v). It was found that ≥ 90% of these learning rates in v could be harmlessly removed by partitioning the gradient vector into B sub-vectors according to the dense Hessian sub-blocks, and call it gb for b = [B]. For each gb, the following quantity is calculated below.
vb = (1 − β2) ∗ mean(gb ◦ gb) + β2 ∗ vb, b = 1, · · · B
Then η/√ vb were used as the learning rate for the parameters associated with gb and this corresponding method is Adam-mini that can outperform Adam, provided that sufficient resources are available to search it out.
Empirically, during verification Adam-mini performs on par or better than AdamW on various language models sized from 125M to 7B for pre-training, supervised fine-tuning, and RLHF. The reduced memory footprint of Adam-mini also alleviates communication overheads among GPUs, thereby increasing throughput. For instance, Adam-mini achieves 49.6% higher throughput than AdamW when pre-training Llama2-7B on 2× A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
Paper : https://arxiv.org/pdf/2406.16793