The capability of LLMs to process long texts is particularly crucial across various domains. Considering the critical role of LLMs in handling long texts, numerous approaches have been suggested to evaluate their long-context capabilities. Such as the Needle In A Haystack(NIAH) test, which uses a more diverse set of non-repetitive personal essays with a context window of 200K.
So one may ask: Does passing the ”needle-in-a-haystack” test—extracting key info from lengthy texts—really indicate that LLMs can handle complex real-world long context problems?
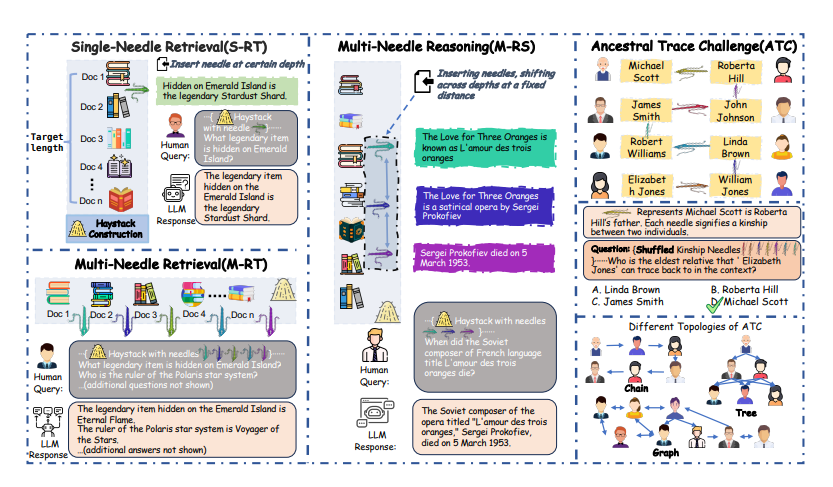
To answer this researcher from Tsinghua University have introduce NeedleBench, a framework consisting of a series of progressively more challenging tasks for assessing bilingual longcontext capabilities, spanning multiple length intervals (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different depth ranges, allowing the strategic insertion of critical data points in different text depth zones to rigorously test the retrieval and reasoning capabilities of models in diverse contexts.
NeedleBench comprises following advanced long-context information capability evaluation methods, 1. Single-Needle Retrieval Task (S-RT): Tests LLMs’ ability to recall a single key information inserted at various positions in a long text, highlighting their precision in navigating and recalling single detail within extensive texts. 2. Multi-Needle Retrieval Task (M-RT): Explores LLMs’ ability to retrieve multiple pieces of related information scattered across a lengthy text, simulating complex real-world queries that require extracting several data points from comprehensive documents. 3. Multi-Needle Reasoning Task(M-RS): Evaluates LLMs’ ability for complex reasoning by extracting multiple pieces of information from long texts and using them to logically answer questions that demand an integrated understanding and reasoning of various text segments.
Furthermore, researchers have also developed the Ancestral Trace Challenge (ATC) test as the simplified proxy for measuring multi-step logical reasoning. During evaluation it was found that current LLMs struggle to handle reasoning tasks with complex logical relationships, even with texts shorter than 2K tokens.
Paper : https://arxiv.org/pdf/2407.11963