@article{cai2024medusa,
title = {Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads},
author = {Tianle Cai and Yuhong Li and Zhengyang Geng and Hongwu Peng and Jason D. Lee and Deming Chen and Tri Dao},
year = {2024},
journal = {arXiv preprint arXiv: 2401.10774}
}
Why is it hard to run inference for large transformer models? Besides the increasing size of SoTA models, there are two main factors contributing to the inference challenge
- Large memory footprint. Both model parameters and intermediate states are needed in memory at inference time. For example, The KV cache should be stored in memory during decoding time; E.g. For a batch size of 512 and context length of 2048, the KV cache totals 3TB, that is 3x the model size. Inference cost from the attention mechanism scales quadratically with input sequence length.
- Low parallelizability. Inference generation is executed in an autoregressive fashion, making the decoding process hard to parallel.
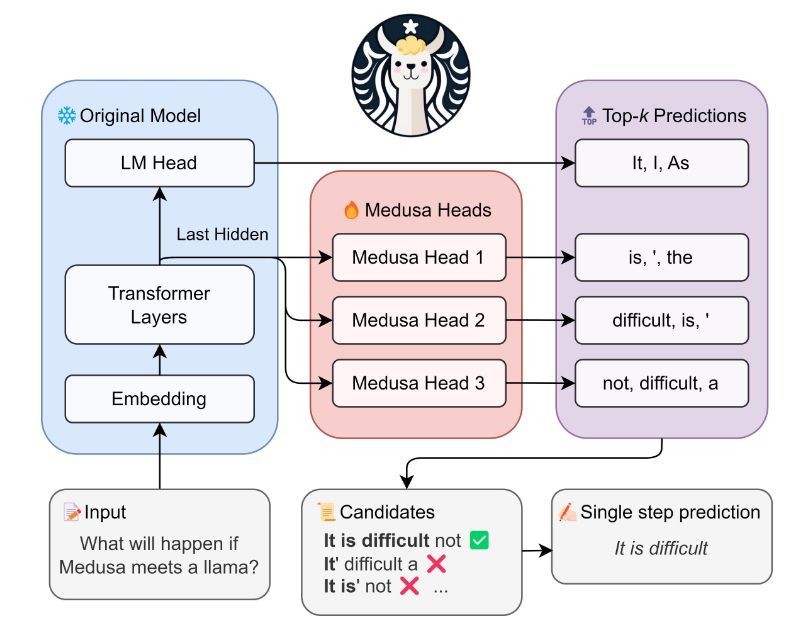
This paper introduces MEDUSA, a method for improving inference in Large Language Models (LLMs) by adding extra decoding heads to predict multiple tokens in parallel. MEDUSA achieves significant speedup without compromising generation quality.
Medusa adds extra “heads” to LLMs to predict multiple future tokens simultaneously. When augmenting a model with Medusa, the original model stays untouched, and only the new heads are fine-tuned during training. During generation, these heads each produce multiple likely words for the corresponding position. These options are then combined and processed using a tree-based attention mechanism. Finally, a typical acceptance scheme is employed to pick the longest plausible prefix from the candidates for further decoding.
So how does Medusa solve the challenges associated with speculative decoding ?
- Instead of introducing a new model, we train multiple decoding heads on the same model.
- The training is parameter-efficient so that even the “GPU-Poor” can do it. And since there is no additional model, there is no need to adjust the distributed computing setup.
- Relaxing the requirement of matching the distribution of the original model makes the non-greedy generation even faster than greedy decoding.
During experimentation, Medusa delivers approximately a 2x speed (1.94x) increase across a range of Vicuna models. Will be interesting to see Medusa’s performance with other open source foundational models.