Large Language Models (LLMs) are prone to off-topic misuse, where users may prompt these models to perform tasks beyond their intended scope. Current guardrails, which often rely on curated examples or custom classifiers, suffer from high false-positive rates, limited adaptability, and the impracticality of requiring real-world data that isn’t available in pre-production.
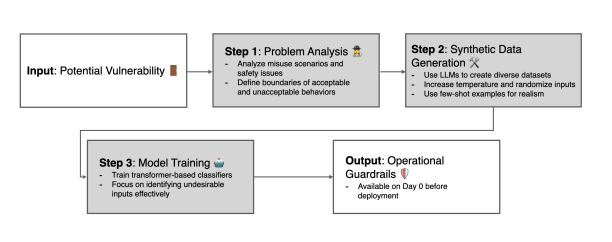
To address this researchers have introduced Flexible Guardrail Development Methodology, which applied to the challenge of off-topic prompt detection for LLMs. This is achieved in 3 phases. First, by thoroughly defining the problem space qualitatively and leveraging an LLM to generate a diverse set of prompts, a synthetic dataset is constructed that serves both as a benchmark and a training resource for off-topic guardrails. Second, a Fine-tuning embedding or cross-encoder model on this synthetic data outperforms heuristic approaches by reducing false positives, and enhancing potential adoption. Finally, by framing this as classifying whether the user prompt is relevant to the system prompt, our guardrail generalises effectively to other misuse categories, including jailbreak and harmful prompts.
Experiments demonstrate that the proposed flexible, data-free guardrail development methodology is effective in detecting offtopic prompts. The fine-tuned classifiers outperform baseline methods in both precision and recall, reducing false positives and enhancing adaptability. By framing the detection task as assessing the relevance between the system prompt and the user prompt, our guardrail generalises effectively to other misuse categories, including jailbreak and harmful prompts.