Key-value (KV) caching plays an essential role in accelerating decoding for transformer-based autoregressive large language models (LLMs). However, the amount of memory required to store the KV cache can become prohibitive at long sequence lengths and large batch sizes.
Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) are some of the widely used methods to reduce the size of the KV cache. Both modify the design of the attention block so that multiple query heads can share a single key/value head, reducing the number of distinct key/value heads by a large factor while only minimally degrading accuracy.
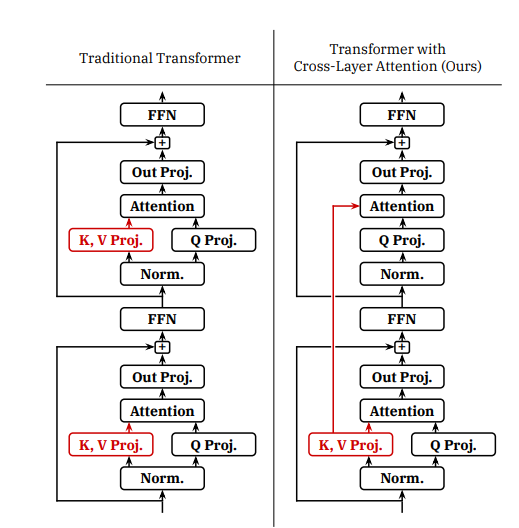
Now the researcher from MIT-IBM has come up with another novel attention design called Cross-Layer Attention (CLA). CLA shares key and value heads between adjacent layers, yielding 2× reduction in KV cache while maintaining nearly the same accuracy as unmodified MQA.
In traditional attention, each layer computes its own separate K and V activations, which must be cached on a per-layer basis during autoregressive decoding. Whereas CLA computes key/value projections for only a subset of layers in the model; the attention blocks in layers without key/value projections reuse the KV activations of previous layers. Only the subset of layers with key/value projections contribute to the KV cache, allowing a reduction in memory footprint relative to traditional architectures which apply a separate key/value projection in each layer.
In experiments training 1B- and 3B-parameter models from scratch, CLA provides a Pareto improvement over the memory/accuracy tradeoffs which are possible with traditional MQA, enabling inference with longer sequence lengths and larger batch sizes than would otherwise be possible.
Paper : https://arxiv.org/pdf/2405.12981