Despite their success, large language models face significant challenges in complex reasoning tasks. Although fine-tuning is shown to be an effective way to improve reasoning capability, most LLMs rely on fine-tuning data distilled or synthesized by superior models like GPT-4. Recently, Reasoning improvements without a superior teacher LLM method are getting more traction but have two major limitations: (1) LLMs often struggle to effectively explore the solution space during reasoning. (2) Even the self-exploration can find high quality reasoning steps, it is difficult for SLMs to tell which reasoning steps are of higher quality or determine which final answers are correct thus it is hard to effectively guide the self-exploration.
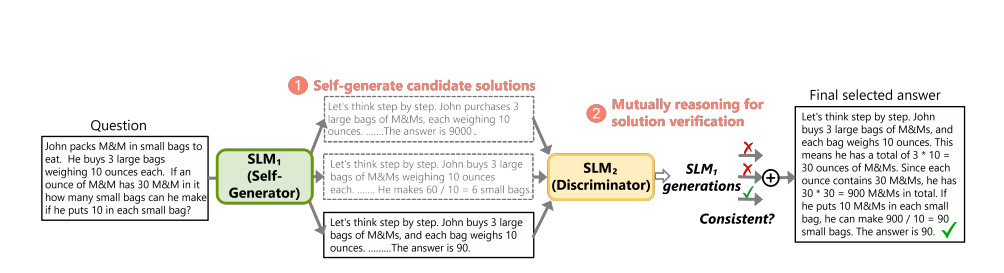
Now researchers have introduced rStar, a self-play mutual reasoning approach that significantly improves reasoning capabilities of small language models (SLMs) without fine tuning or superior models. rStar decouples reasoning into a self-play mutual generation-discrimination process. First, a target SLM augments the Monte Carlo Tree Search (MCTS) with a rich set of human-like reasoning actions to construct higher quality reasoning trajectories. Next, another SLM, with capabilities similar to the target SLM, acts as a discriminator to verify each trajectory generated by the target SLM. The mutually agreed reasoning trajectories are considered mutually consistent, thus are more likely to be correct.
In general, self-play mutual reasoning is a generation-discrimination process: (1) a self-generator augments the target SLM to generate candidate reasoning trajectories using MCTS; (2) the discriminator uses another SLM to provide unsupervised feedback on each trajectory based on partial hints; (3) based on this feedback, the target SLM decides a final reasoning trajectory as the solution.
Extensive experiments across five SLMs demonstrate rStar can effectively solve diverse reasoning problems, including GSM8K, GSM-Hard, MATH, SVAMP, and StrategyQA. Remarkably, rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2-7B, from 36.46% to 81.88% for Mistral-7B, from 74.53% to 91.13% for LLaMA3-8BInstruct.
Paper : https://arxiv.org/pdf/2408.06195