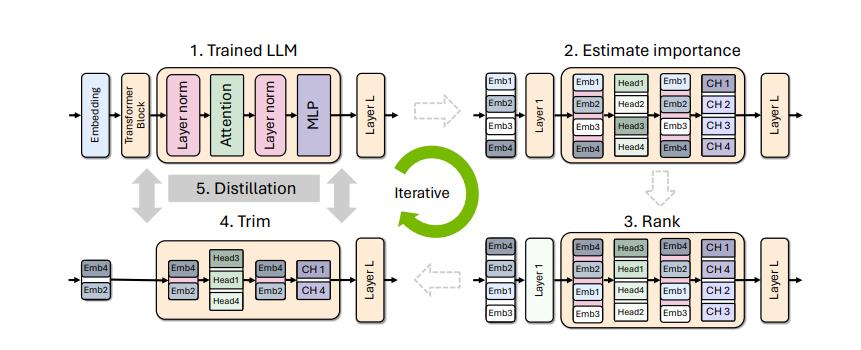
Training multiple multi-billion parameter large language models from scratch is extremely time-, data- and resource-intensive. However, recent work has demonstrated the effectiveness of combining weight pruning with knowledge distillation to significantly reduce the cost of training LLM model families. Now researchers from Nvidia use Minitron compression strategy on two state-of-the-art models: Llama 3.1 8B and Mistral NeMo 12B, compressing them down to 4B and 8B parameters.
Due to unavailability of original training data, researchers used a slightly fine-tuned version of the teacher model then the distillation is performed by minimizing KL divergence on the logits, with the original model as the teacher and the pruned model as the student. Further two distinct pruning strategies: (1) depth pruning and (2) joint hidden/attention/MLP (width) pruning is used, and evaluate the results on common benchmarks from the LM Evaluation Harness. The models are then aligned with NeMo Aligner and tested in instruct-tuned versions.
Minitorn compression strategy yields state-of-the-art Llama-3.1-Minitron-4B models and MN-Minitron-8B which outperforms all similarly sized models across the board on common language modeling benchmarks. In terms of runtime inference performance measured using TensorRT-LLM, the MN-Minitron-8B model provides an average speedup of 1.2× over the teacher Mistral NeMo 12B model. Similarly, the Llama-3.1-Minitron-4B models provide an average speedup of 2.7× and 1.8× for the depth and width pruned variants, respectively, compared to the teacher Llama 3.1 8B model.
Paper : https://arxiv.org/pdf/2408.11039