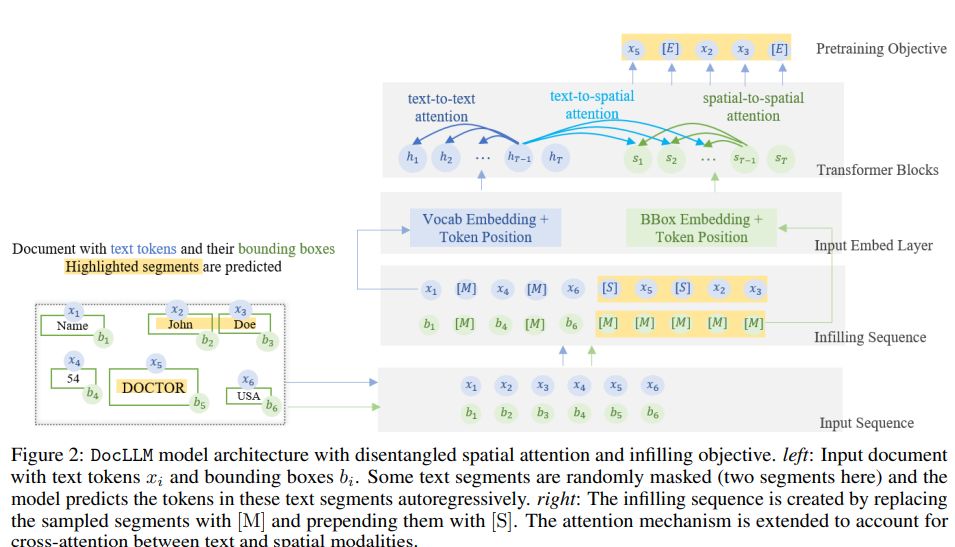
Introducing DocLLM, a groundbreaking generative language model that can understand visually rich documents without the need for expensive image encoders. DocLLM uses a disentangled attention mechanism that captures the interdependencies between text and layout, making it possible to handle irregular layouts and heterogeneous content in visual documents.
DocLLM’s pre-training objective focuses on infilling missing text segments, and the pre-trained model is fine-tuned using instructions from various datasets, including visual question answering, natural language inference, key information extraction, and document classification.
Evaluated against comparable models, DocLLM outperforms on 14 out of 16 datasets and generalizes to 4 out of 5 unseen datasets. Its awareness of multi-page documents and page breaks enhances its ability to understand long documents.
DocLLM can enable the use of more types of data for pre-training language models, allowing documents with complex layouts to be used without much preprocessing. Its cohesive text blocks for pre-training enable meaningful infilling.