Introducing DistAttention, a distributed attention algorithm, and DistKV-LLM, a distributed LLM serving system, to improve the performance and resource management of cloud-based LLM services. The system achieved significant throughput improvements and supported longer context lengths compared to existing systems
Traditionally, serving LLMs with long context lengths poses challenges due to the dynamic and growing memory requirements of the attention layer’s key-value (KV) cache. This makes efficient resource management difficult. Introducing DistAttention, a novel distributed attention algorithm that partitions the KV cache into smaller blocks (“rBlocks”) to enable distributed processing and storage. The paper also introduces DistKV-LLM, a distributed LLM serving engine that coordinates memory usage across GPUs and CPUs in a data center. It manages the distributed KV cache through two components the rManager and gManager.
The rManager virtualizes memory for each instance and handles local and remote memory requests. The gManager maintains a global view of memory usage and facilitates allocation between instances. Techniques like overlapping communication and computation, a memory optimization algorithm (DGFM), and a coordination protocol are proposed to improve performance.
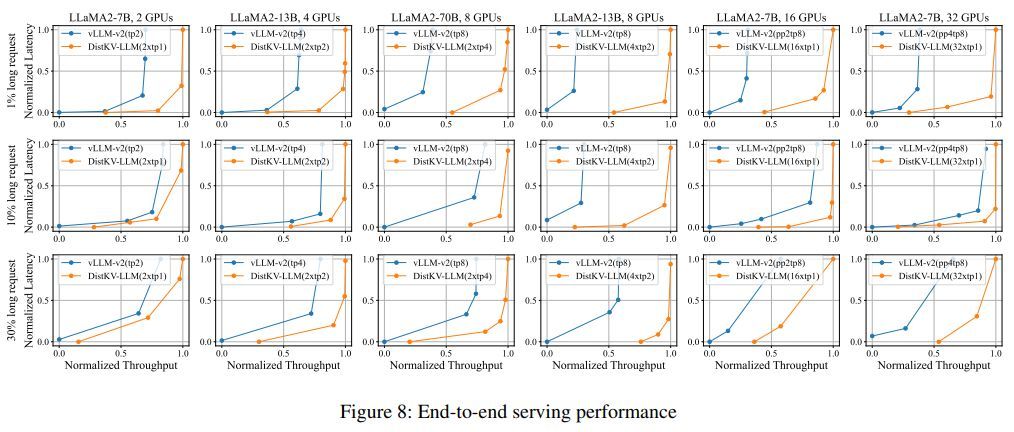
Evaluation on a 32 GPU cluster shows the system supports context lengths 2-19x longer than prior work, with 1.03-2.4x higher throughput. It achieves efficient resource utilization for long-context LLM serving in distributed environments. In summary, the key novelty lies in DistAttention’s distributed approach to processing the attention layer, and DistKV-LLM’s coordinated management of the distributed KV cache memory across