With the development of Multimodal Large Language Models (MLLMs), there is an increasing need for embedding models to represent multimodal inputs. Although CLIP shows impressive results in text-image retrieval, it struggles to represent interleaved visual and language inputs.
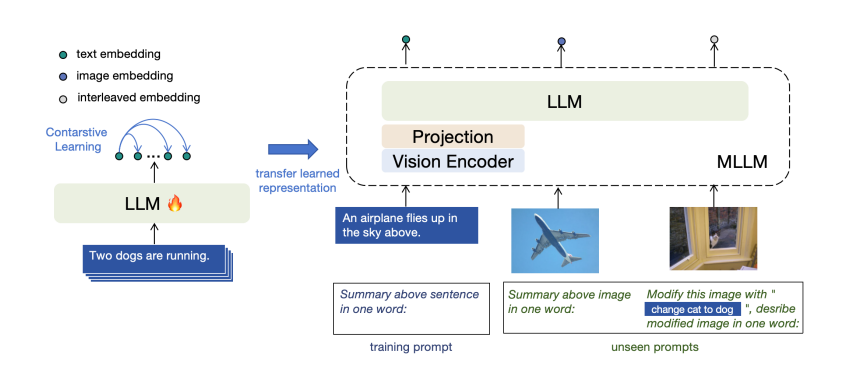
To address this researchers from Microsoft have introduced E5-V, a new framework designed to adapt MLLMs for achieving universal multimodal embeddings. E5-V achieves this by using a prompt based method to explicitly instruct MLLMs to represent multimodal inputs into words. This unifies multimodal embeddings into the same space, which directly removes the modality gap in multimodal embeddings. Now MLLMs are able to achieve robust multimodal embedding performance through single modality training with only on text inputs. This eliminates the need for expensive multimodal training data collection.
Further, by focusing solely on text data, ES-V removes other components, such as the visual encoder, in the MLLMs during training and decreases the input size, significantly reducing the training by 95%. Apart from this there are several advantages to representing multimodal information with MLLMs: (1) MLLMs can initially learn to represent multimodal information according to their meanings with prompt, benefiting from interleaved visual and language training. (2) MLLMs are capable of representing interleaved visual and language inputs to handle tasks like composed image retrieval. (3) MLLMs have stronger language understanding and reasoning capabilities compared to CLIP.
E5-V was validated across various tasks: text-image retrieval, composed image retrieval, sentence embeddings, and image-image retrieval. By comparing E5-V with the strong baselines of each task, It was found that E5-V was effective in representing multimodal information, which achieves competitive performance on all tasks as a universal multimodal embeddings model trained on text pairs only.
Paper : https://arxiv.org/pdf/2407.12580