LLM Efficiency
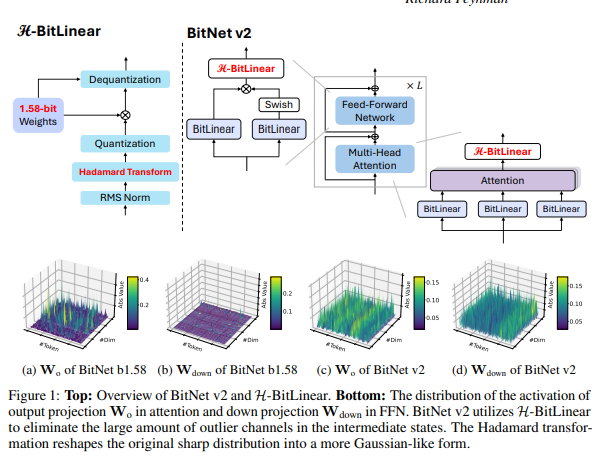
H-BitLinear applies an online Hadamard transformation before activation quantization, reshaping outlier-heavy intermediate states into Gaussian-like distributions that survive native 4-bit quantization.
Recently pioneering work like BitNet b1.58 demonstrated that 1.58-bit LLMs can match full-precision performance while drastically reducing inference costs (latency, memory, throughput, energy) and it’s all possible due to lower bit-width activations, which is crucial for maximizing hardware utilization, particularly for efficient kernel design in batched inference scenarios.
However research highlights a key challenge: the non-uniform distribution of activations within LLMs. While inputs to attention and feed-forward network (FFN) layers often exhibit Gaussian-like distributions amenable to quantization, their intermediate states (outputs before final projection) contain significant outliers, hindering aggressive low-bit quantization.
To address this researchers have introduced BitNet v2, a novel framework enabling native 4-bit activation quantization for 1-bit LLMs. The core innovation is H-BitLinear, a novel linear layer replacing the standard output projections in attention and down projections in FFNs. H-BitLinear applies an online Hadamard transformation before activation quantization. This strategically reshapes the sharp, outlier-prone distributions of intermediate states into more manageable, Gaussian-like forms, significantly reducing the impact of outliers in 1.58-bit models.
BitNet v2 is implemented using LLaMA-like components, including RMS normalization, SwishGLU and removing all bias. Compared to BitNet, H-BitLinear is used for Wo in attention and Wdown in FFN layers to deal with outlier channels of intermediate states. BitNet v2 is trained with 1.58-bit weights and INT8 activations from scratch, then continue-trained with INT4 activations for all linear layers except input/output embedding.
Extensive experiments demonstrate that 4-bit BitNet v2 variant achieves performance comparable to BitNet a4.8 while offering superior computational efficiency for batched inference scenarios.
The 4-bit BitNet v2 matches BitNet a4.8 quality while delivering superior compute efficiency for batched inference.