Recent Large Language Models (LLMs) can support contexts up to millions of tokens in length However, processing such long sequences with LLMs requires substantial computational and memory resources due to the quadratic complexity of the self-attention mechanism. To address these challenges, various techniques have been proposed such as Flash Attention and Ring Attention.
In many long-context tasks, the input consists of a long context followed by a short query and a short answer. The information needed for answering the query is often localized within small parts of the context, meaning context tokens need only attend to nearby tokens, while query tokens need to attend to all prior tokens.
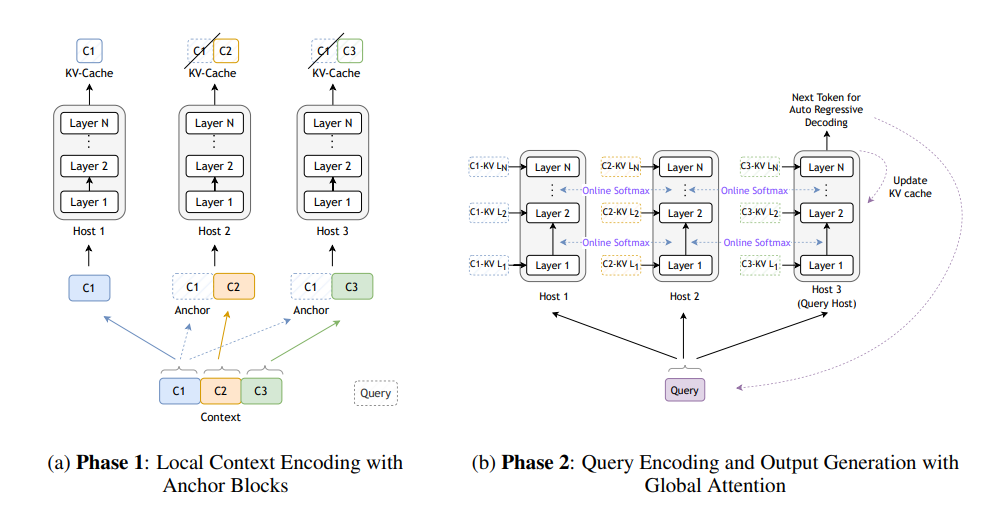
Based on this observation, researchers have introduced Star Attention, a novel algorithm for efficient LLM long-context inference. Star Attention utilizes a two-phase approach 1. Context Encoding: The context is divided into contiguous blocks and distributed across “context” hosts, with each host also receiving a copy of the first block (an “anchor block”). Hosts compute self-attention only for their assigned blocks, without communicating with each other, reducing attention complexity from quadratic to linear with respect to context length. 2. Query Encoding and Token Generation: The query is replicated across all hosts where it initially attends to the KV cache on each host. Global attention is then computed by aggregating the results at a designated “query” host by efficiently communicating a single vector and scalar per token from each context host. Only the query host updates its KV cache during this stage.
Star Attention enables the context length to scale linearly with the number of hosts by distributing the context processing across multiple hosts. Star Attention is compatible with most Transformer Based LLMs trained with global attention, operating seamlessly out-of-the-box without additional model fine-tuning.
During Evaluating Star Attention for Llama3.1-8B and Llama3.1-70B on several long-context benchmarks. Star Attention achieves up to 11 times faster inference while maintaining 95-100% of the baseline accuracy. Furthermore, Star Attention can be combined with other LLM optimization methods like Flash Attention or KV cache compression, allowing for additional speedup enhancements during inference.
Paper: Star Attention: Efficient Long-Context Inference with Non-Global Attention