Dataset Distillation aims to compress a large dataset into a significantly more compact, synthetic one without compromising the performance of the trained models. To achieve this, existing methods use the agent model to extract information (Information Extraction) from the target dataset and embed (Information Embedding) it into the distilled dataset. Consequently, the quality of extracted and embedded information determines the quality of the distilled dataset. However, these methods introduce misaligned information in both information extraction and embedding stages.
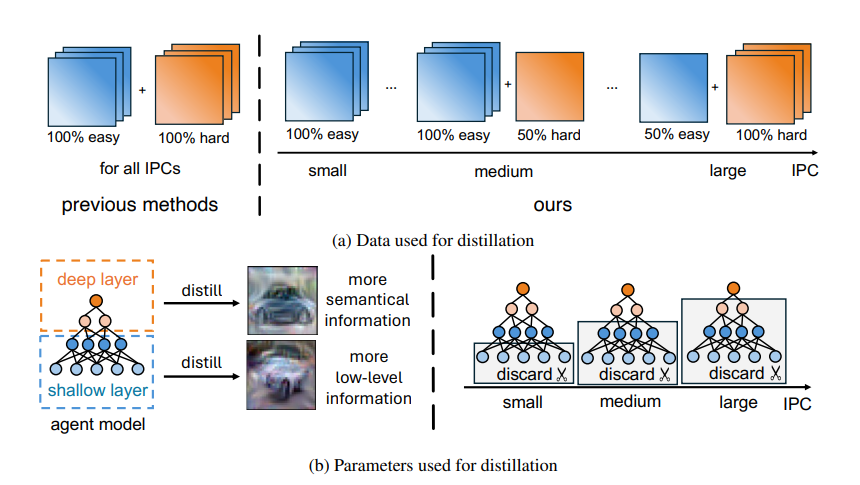
To alleviate this, researchers have proposed Prioritize Alignment in Dataset Distillation (PAD), which aligns information from the following two perspectives. 1) Prune the target dataset according to the compression ratio to filter the information that can be extracted by the agent model. 2) Use only deep layers of the agent model to perform the distillation to avoid excessively introducing low-level information. This simple strategy effectively filters out misaligned information and brings non-trivial improvement for mainstream matching-based distillation algorithms.
Through experiments, it was found that the two-step alignment strategy is effective for distillation methods based on matching gradients, distributions, and trajectories and the proposed novel method Prioritize Alignment in Dataset Distillation (PAD) achieves state-of-the-art (SOTA) performance.
Paper : https://arxiv.org/pdf/2408.03360