Recently, LLM-based agents have shown promise for real-world tasks like web navigation, but they still struggle with complex, long-term tasks. Unlike these models, humans however excel at tackling intricate tasks by learning and reusing past experiences to guide future actions.
To build agents that can similarly benefit from this process researchers have introduced Agent Workflow Memory (AWM), a method for inducing commonly reused routines, i.e., workflows, and selectively providing workflows to the agent to guide subsequent generations.
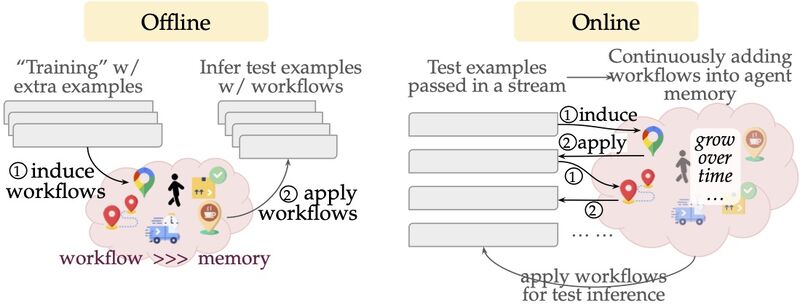
AWM starts with a basic set of built-in actions and solves new tasks in a streaming manner, continuously inducing workflows from the task at hand, e.g., learning to “find a place by its name” from the first few examples. Moreover, AWM continues to build more complex workflows on top of new experiences and previously acquired workflows. For example, the “find a place by its name” workflow, once induced, effectively serves as a subgoal to build a more complex workflow “get the zip code of a place.” Such continual learning mechanisms create a snowball effect to induce and apply increasingly complex workflows while expanding the agent memory, often yielding a substantial performance gap over a vanilla agent that does not adapt.
Further, AWM flexibly applies to both offline and online scenarios offline: when additional (e.g., training) examples are available, agents induce workflows from ground-truth annotated examples and online: without any auxiliary data, agents induce workflows from past experiences on the fly.
While evaluating, AWM was experimented on two major web navigation benchmarks — Mind2Web and WebArena. AWM substantially improves the baseline results by 24.6% and 51.1% relative success rate on Mind2Web and WebArena while reducing the number of steps taken to solve WebArena tasks successfully. Furthermore, online AWM robustly generalizes in cross-task, website, and domain evaluations, surpassing baselines from 8.9 to 14.0 absolute points as train-test task distribution gaps widen.
Paper : https://arxiv.org/pdf/2409.07429