The ability to accurately interpret complex visual information is a crucial topic of multimodal large language models (MLLMs). Recent work indicates that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis. A number of recent MLLMs achieve this goal using a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts.
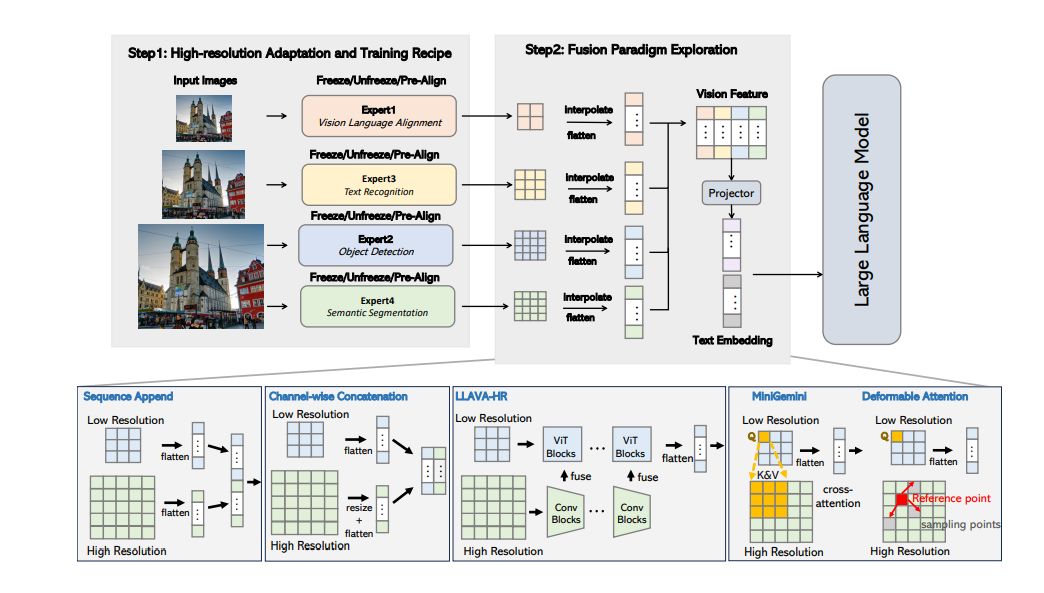
In order to address this issue researchers investigate the MLLM design space with multiple vision encoders, aiming to identify optimized design choices and improve the MLLM perception including various types of vision experts pre-trained on different tasks and resolutions. Next series of popular fusion strategies were compared under controlled settings, including Sequence Append, Channel Concatenation, LLaVA-HR, Mini-Gemini, and Deformable Attention. Finally, the optimal fusion design is further extended to multiple vision encoders to form a strong MLLM perception.
Researchers then conclude their findings into a family of Vision-Centric High-Resolution Multimodal LLMs called Eagles, which presents a thorough exploration to strengthen multimodal LLM perception with a mixture of vision encoders and different input resolutions. The model contains a channel-concatenation-based “CLIP+X” fusion for vision experts with different architectures (ViT/ConvNets) and knowledge (detection/segmentation/OCR/SSL). The resulting family of Eagle models support up to over 1K input resolution and obtain strong results on multimodal LLM benchmarks, especially resolution-sensitive tasks such as optical character recognition and document understanding.
Paper : https://arxiv.org/pdf/2408.15998