Large Language Models (LLMs) based on Mixture-of-Experts (MoE) architectures are showing remarkable performance on various tasks. By activating a subset of experts inside feed-forward layers with a gating mechanism, such models scale up model size and improve model performance with a small computation overhead. However, running them on resource-constrained settings, where GPU memory resources are not abundant, is challenging due to huge model sizes.
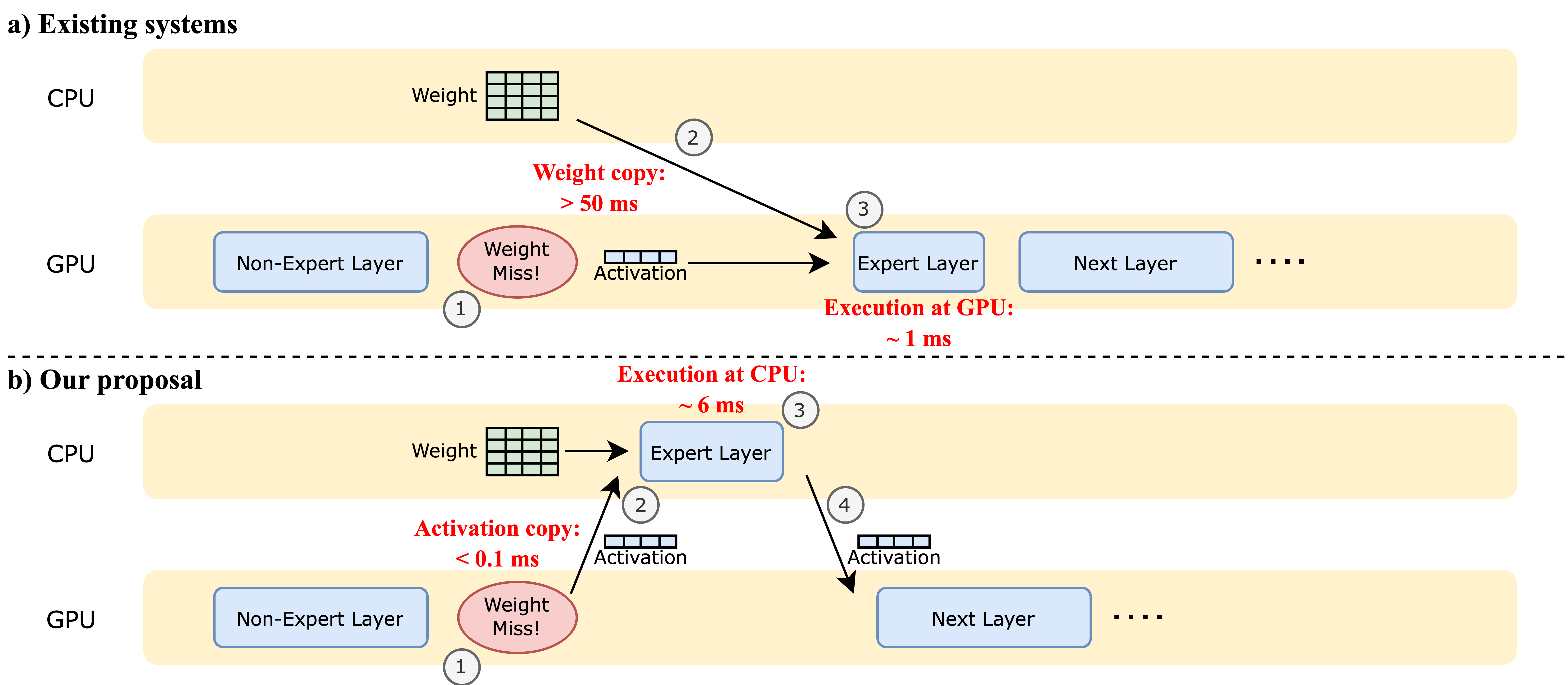
To address this paper proposes Fiddler, a fast inference system for LLMs based on Mixture-of-Experts (MoE) architecture at local devices. It allows you to run an unquantized Mixtral-8x7B model (>90GB of parameters) with >3 token/s on a single 24GB GPU. The key idea behind Fiddler is to use the CPU’s computation power. Existing offloading systems primarily utilize the memory resources available on the CPU, while the computation mainly occurs on the GPU. The typical process involves: (1) When some expert weights are missing from the GPU memory, (2) they are copied from the CPU memory to the GPU memory, then (3) GPU executes the expert layer. Although GPU execution is faster, the data movement introduces significant overhead.
On the other hand, Fiddler uses CPU computation resources in addition to memory resources. The process is as follows: (1) when some expert weights are missing on the GPU memory, (2) it copies the activation values from the GPU memory to the CPU memory, instead of copying the weights. (3) The computation of the expert layer then happens on the CPU, and (4) the output activation after the expert is copied back to the GPU.
This approach significantly reduces the latency of CPU-GPU communication, especially since the size of activations is considerably smaller than the weight size (batch_size x 4096 versus 3 x 4096 x 14336 per expert for the Mixtral-8x7B) for a small batch size. Despite slower computation speeds on the CPU compared to the GPU, avoiding the weight copying process makes this approach more efficient.
Compared with DeepSpeed-MII and Mixtral offloading, Fiddler is on average faster by 19.4 and 8.2 times for Environment 1, and by 22.5 and 10.1 times for Environment 2.
Paper : https://arxiv.org/pdf/2402.07033.pdf
Github : https://github.com/efeslab/fiddler