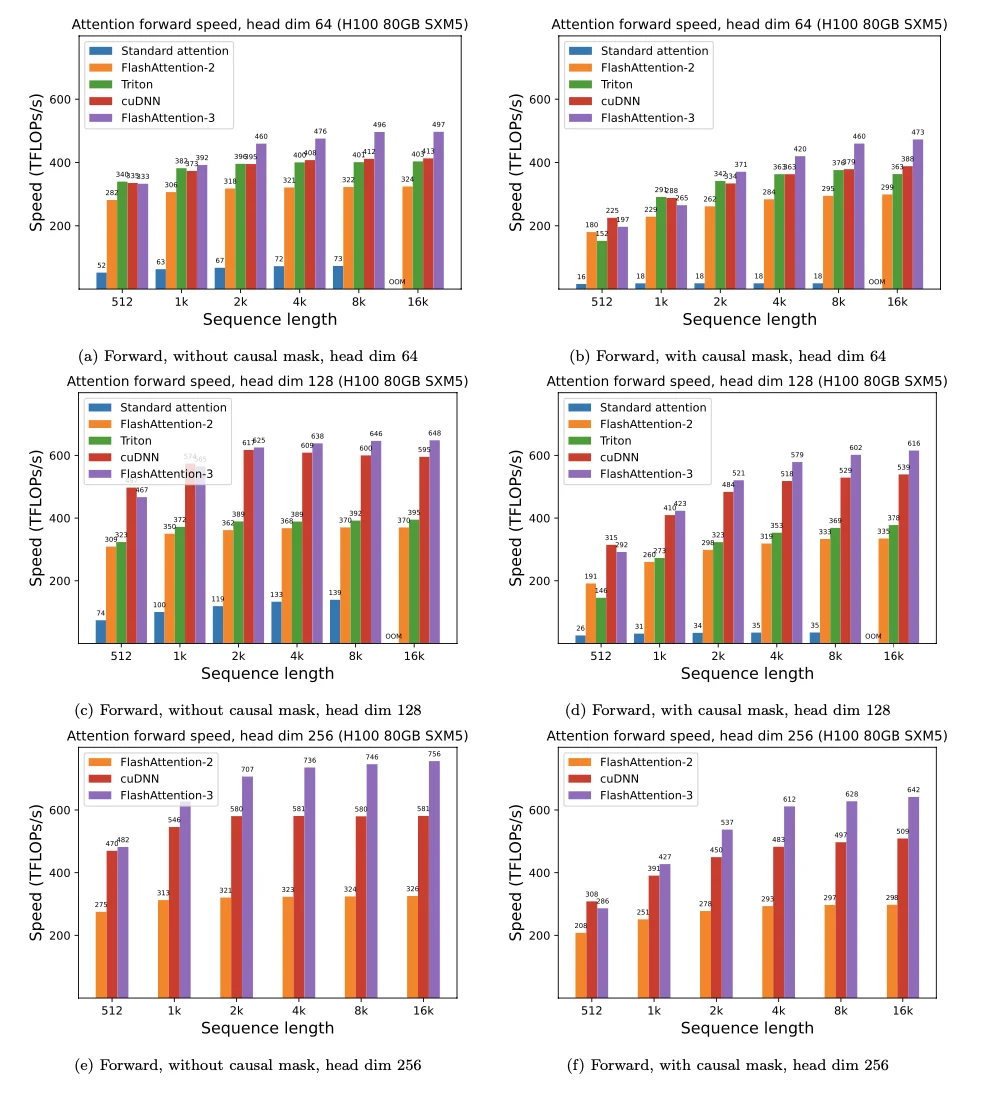
FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is used across various libs to accelerate Transformer training and inference. However, despite its success, FlashAttention has yet to take advantage of new capabilities in modern hardware, with FlashAttention-2 achieving only 35% utilization of theoretical max FLOPs on the H100 GPU (Hopper).
Now researchers have introduced FlashAttention-3 which makes use of the following three new features of Hopper, using powerful abstractions from NVIDIA’s CUTLASS library. • WGMMA (Warpgroup Matrix Multiply-Accumulate), which makes use of the new Tensor Cores on Hopper, with much higher throughput than the older mma.sync instruction in Ampere (A100). • TMA (Tensor Memory Accelerator), a special hardware unit that accelerates the transfer of data between global memory and shared memory, taking care of all index calculation and out-of-bound prediction • Low-precision with FP8. This doubles the Tensor Core throughput (e.g. 989 TFLOPS with FP16 and 1978 TFLOPS with FP8), but trades off accuracy by using fewer bits to represent floating point numbers.
Overall, FlashAttention-3 utilize three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for FP8 low-precision.
FlashAttention-3, by incorporating above technique, 1.5-2.0x faster than FlashAttention-2 with FP16, up to 740 TFLOPS, i.e., 75% utilization of H100 theoretical max FLOPS. With FP8, FlashAttention-3 reaches close to 1.2 PFLOPS, with 2.6x smaller error than baseline FP8 attention.