Finally, the first production-grade commercially available Mamba-based model delivering best-in-class quality and performance is here. Introducing Jamba, a novel architecture which combines Attention and Mamba layers, with MoE modules. Here are some key features of Jamba
- 3X throughput on long contexts compared to Mixtral 8x7B
- Democratizes access to a massive 256K context window
- The only model in its size class that fits up to 140K context on a single GPU
So how does Jamba provide flexibility for balancing performance and memory requirements, while the previous Mamba-Transformer based models were not able to do so ?
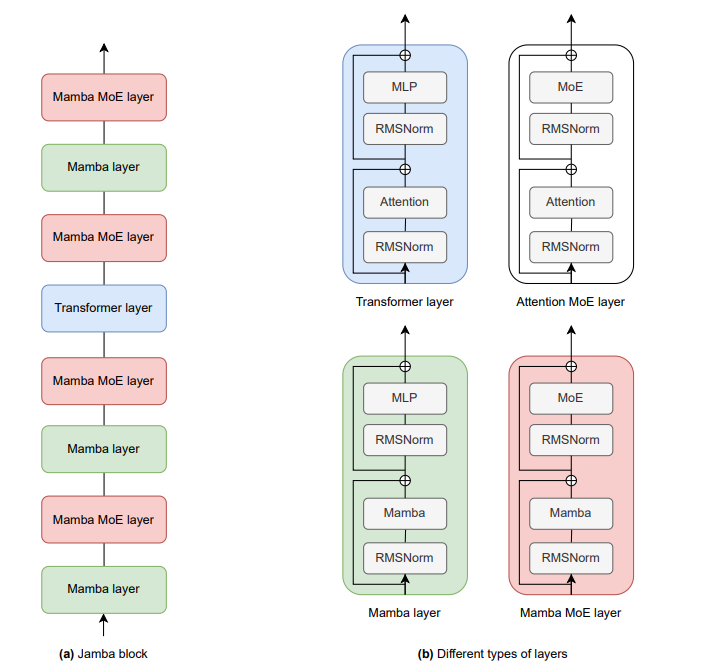
It all comes down to Jamba architecture choice, which aims to provide not only a small number of active parameters but also an 8x smaller KV cache compared to a vanilla Transformer. The basic component is a Jamba block, which may be repeated in sequence. Each Jamba block is a combination of Mamba or Attention layers. Each such layer contains either an attention or a Mamba module, followed by a multi-layer perceptron (MLP). Further, In Jamba some of the MLPs may be replaced by MoE layers, which helps increase the model capacity while keeping the active number of parameters, and thus the compute, small
In summary, the different degrees of freedom in the Jamba architecture are:
* l: The number of layers. * a : m : ratio of attention-to-Mamba layers.
* e: how often to use MoE instead of a single MLP. * n: total number of experts per layer. * K: number of top experts used at each token.
Given this design space, Jamba provides flexibility in preferring certain properties over others. For example, increasing m and decreasing a, i.e, increasing the ratio of Mamba layers at the expense of attention layers, reduces the required memory for storing the key-value cache thus reducing overall memory space. Increasing the ratio of Mamba layers also improves throughput, especially at long sequences. However, decreasing a might lower the model’s capabilities. Other architecture details are standard, including grouped-query attention (GQA), SwiGLU activation function, and load balancing for the MoE. The vocabulary size is 64K. The tokenizer is trained with BPE and each digit is a separate token.