Large Language Models (LLMs) have demonstrated remarkable performance in a wide range of natural language processing tasks, but their increasing size has posed challenges for deployment and overall cost. One approach to address these challenges is to use post-training quantization to create low-bit models for inference moving from 16 bits to lower bits, such as 4-bit variants. However, post-training quantization is sub-optimal, even though it is widely used in industry LLMs.
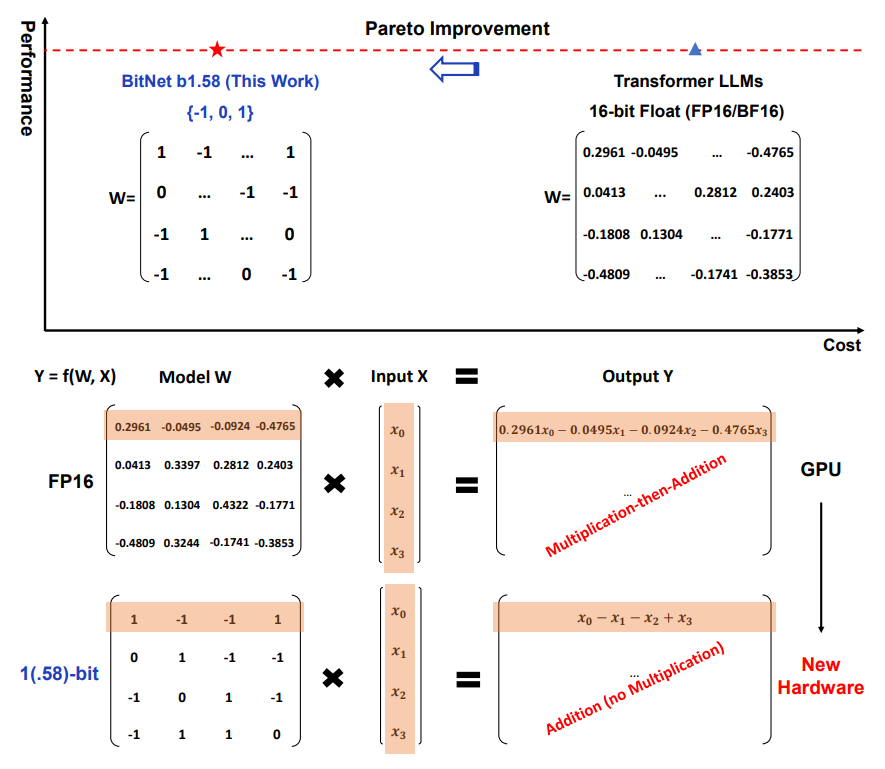
Recent work on 1-bit model architectures, such as BitNet, presents a promising direction for reducing the cost of LLMs while maintaining their performance. BitNext advantages include (1) matrix multiplication of BitNet only involves integer addition (2) lower memory footprint thereby reducing the cost and time of loading weights from DRAM, leading to faster and more efficient inference.
Continuing on this work, researchers developed a new 1-bit LLM variant called BitNet b1.58, where every parameter is ternary, taking on values of {-1, 0, 1}. An additional value of 0 to the original 1-bit BitNet, resulting in 1.58 bits in the binary system. BitNet b1.58 retains all the benefits of the original 1-bit BitNet. Furthermore, BitNet b1.58 offers two additional advantages. (1) its modeling capability is stronger due to its explicit support for feature filtering, made possible by the inclusion of 0 in the model weights, which can significantly improve the performance of 1-bit LLMs.(2) BitNet b1.58 can match full precision (i.e., FP16) baselines in terms of both perplexity and end-task performance, starting from a 3B size, when using the same configuration (e.g., model size, training tokens, etc.).
During experimental comparison between BitNet b1.58 and LLaMA LLM. It shows that BitNet b1.58 starts to match full precision LLaMA LLM at 3B model size in terms of perplexity, while being 2.71 times faster and using 3.55 times less GPU memory. In particular, BitNet b1.58 with a 3.9B model size is 2.4 times faster, consumes 3.32 times less memory, but performs significantly better than LLaMA LLM 3B.
So what next from here ? Yes 1-bit Mixture-of-Experts (MoE) LLMs.
Paper : https://arxiv.org/abs/2402.17764