Large language models (LLMs) have been instrumental in pushing the boundaries of various real-world applications mostly which are associated with long-sequence inputs, such as long-document question answering and summarization. Unfortunately, the learning and deployment of long context LLMs are still challenging mostly due to cost and overall accuracy.
So are long-context tasks are short-context solvable ?
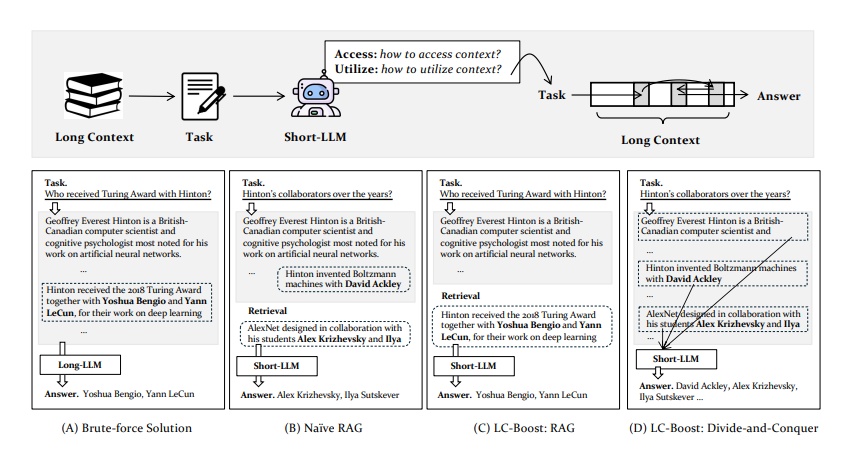
To address this researchers have proposed a novel framework called LC-Boost (Long-Context Bootstrapper), which enables a short-LLM to address the long-context tasks in a bootstrapping manner. LC-Boost operates with two critical reasoning steps: 1) Access : how to access the appropriate part of context within the input, 2) Utilize: how to make effective use of the accessed context. By adaptively accessing and utilizing the context based on the presented tasks, LC-Boost can serve as a general framework to handle diversified long-context processing problems.
Let’s take the toy examples to better illustrate the mechanism of LC-Boost. There are two common approaches to tackle long-context problems: (A) the brute-force method based on long-LLMs, (B) the surrogate methods, like Naive RAG. Despite correctness, brute-force method is unnecessarily expensive due to the processing of the entire context simultaneously. whereas in case of Naive RAG It is hard to handle problems like information aggregation, which leads to the incomplete answer.
In contrast, LC-Boost is able to handle general long-context tasks thanks to the proper reasoning of how to access and utilize the long-context information based on each specific task (C), it can directly access the needed information via retrieval and generate the answer based on RAG. Further LG-Boot can also process the entire context in a divide-and-conquer manner (D), processes the long-context via sequential scan, which correctly solves the problem based on the comprehensively collected information.
LC-Boost underwent extensive evaluation across real-world and synthetic tasks, including question-answering and summarization of lengthy documents. Results showed it matched or even exceeded the performance of brute-force methods, like GPT-4-128K, often due to its ability to eliminate irrelevant context. Notably, LC-Boost outperformed short-LLM surrogates with predefined context access, highlighting the significance of reasoning and adaptability in its success.
Paper : https://arxiv.org/pdf/2405.15318