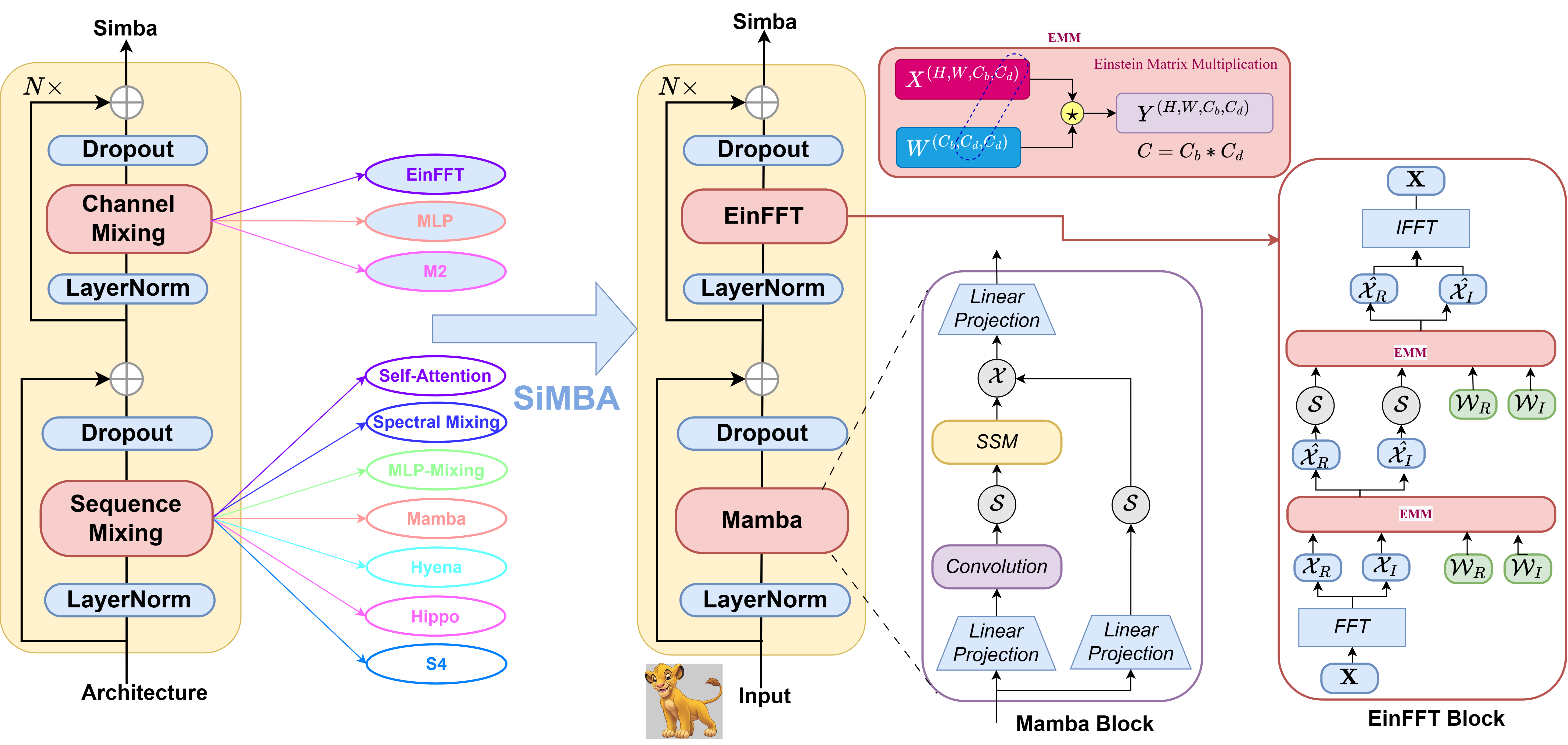
Recently, Structured State Space models (SSM) such as Mumba have been pitched as an for Transformer based models especially when it comes to increase efficiency and performance for processing longer input sequences. Mamba, while being the state-of-the-art SSM, is good for longer input sequences but has a stability issue when scaled to large networks for computer vision datasets. This is evident in Mamba when all eigenvalues of matrix A are negative real numbers, which leads to the problem of vanishing/exploding gradients.
To address this, researchers from Microsoft have proposed SiMBA (Simplified Mamba-based Architecture). SiMBA introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling. EinFFT is specifically designed for complex number representations of frequency components, enabling the effective capture of key patterns in Image patch data with a global view and energy compaction.
SiMBA illustrates an important trade-off between performance and scalability. Mamba by itself may have stability issues for large networks. Mamba combined with MLP for channel mixing bridges the performance gap for small-scale networks, but may have the same stability issues for large networks. Mamba combined with EinFFT solves stability issues for both small-scale and large networks.
Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers. Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets.