Large Multimodal Models (LMMs) have attracted significant attention with their potential applications and emergent capabilities. However, recent works have demonstrated that large-scale and high-quality data are essential for training robust LMMs. Lack of such data has widened the gap between open-source models and proprietary ones in terms of access to open weights, training recipes, and curated datasets.
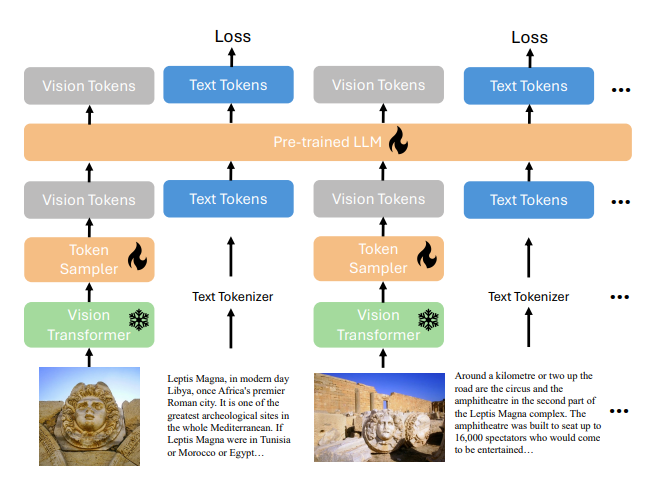
In response to these challenges, researcher have introduce xGen-MultiModal or xGen-MM (BLIP-3), a new framework designed to scale up LMM training by utilizing an ensemble of multimodal interleaved datasets, curated caption datasets, and other publicly available datasets. In xGen-MM (BLIP-3) uses scalable vision token sampler and simplifies the training objectives to focus solely on the auto-regressive loss of text tokens in a multimodal context. xGen-MM uses Free-form interleaved images and texts from the ensembled interleaved and caption datasets with each modality undergoing a separate tokenization process to be fed into the pre-trained LLM in natural order. A standard auto-regressive loss is then applied to the text tokens. The Vision Transformer is kept frozen during training, while all other parameters, including the token sampler and the pre-trained LLM, are trained.
Further, researchers have also released scaling up the training data: MINT-1T , a trillion-token scale interleaved dataset; BLIP3-KALE, a knowledge-augmented high-quality dense captions dataset. BLIP3-OCR-200M, a large-scale dataset with dense OCR annotations; and BLIP3-GROUNDING-50M, a large-scale visual grounding dataset.
Paper : https://arxiv.org/pdf/2408.08872