State-of-the-art large language models (LLMs) such as Gemin and GPT-4 are generally trained in three stages. First, LLMs are pre-trained on large corpora of knowledge using next-token prediction Second, the pre-trained models are fine-tuned to follow instructions via supervised fine-tuning (SFT) Lastly, reinforcement learning from human feedback (RLHF) is used to further increase the quality of generations. Fine-tuning LLMs with reinforcement learning (RL) is challenging, notably since it can cause forgetting of pre-trained knowledge and can cause reward hacking.
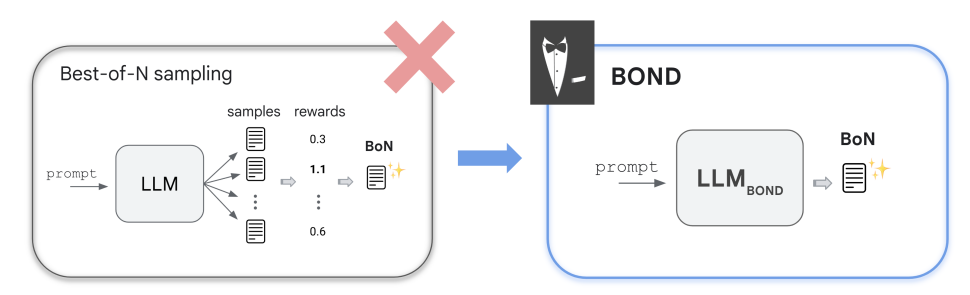
Best-of-N inference-time strategy is widely used to handle this. Best-of-N sampling draw 𝑁 candidate generations from the reference SFT model and select the one with the highest reward according to the RM. This strategy empirically achieves excellent reward-KL trade-offs but increases the computational cost by a factor of 𝑁.
Now researchers from Google’s proposed BOND approach aims at obtaining a fine-tuned policy that can directly sample the Best-of-N generation. This would inherit the quality of Best-of-N sampling, while requiring a single sample at inference time. This by distilling the Best-of-N strategy into the policy via online distribution matching.
BOND first minimizes the forward KL divergence using samples from the Best-of-N strategy, leading to a standard imitation learning setup with a mode covering behavior. Then it minimizes the backward KL, leading to a new form of quantile-based advantage, which does not depend on the reward scale, and corresponds to a mode seeking behavior. Then, linear combination of forward and backward KL is used, also known as Jeffreys divergence, which retains the best of both approaches. Finally, this J-BOND (J for Jeffreys), a novel, stable, efficient and practical RLHF algorithm is used to align LLMs.
Paper : https://arxiv.org/pdf/2407.14622