Recent studies have demonstrated how Large Language Models (LLMs) can be utilized to learn skills for improved decision-making in interactive environments. However, learning skills in adversarial environments with multiple agents presents a significant challenge for LLMs, as it requires accounting for the responses of other players or environment to their actions.
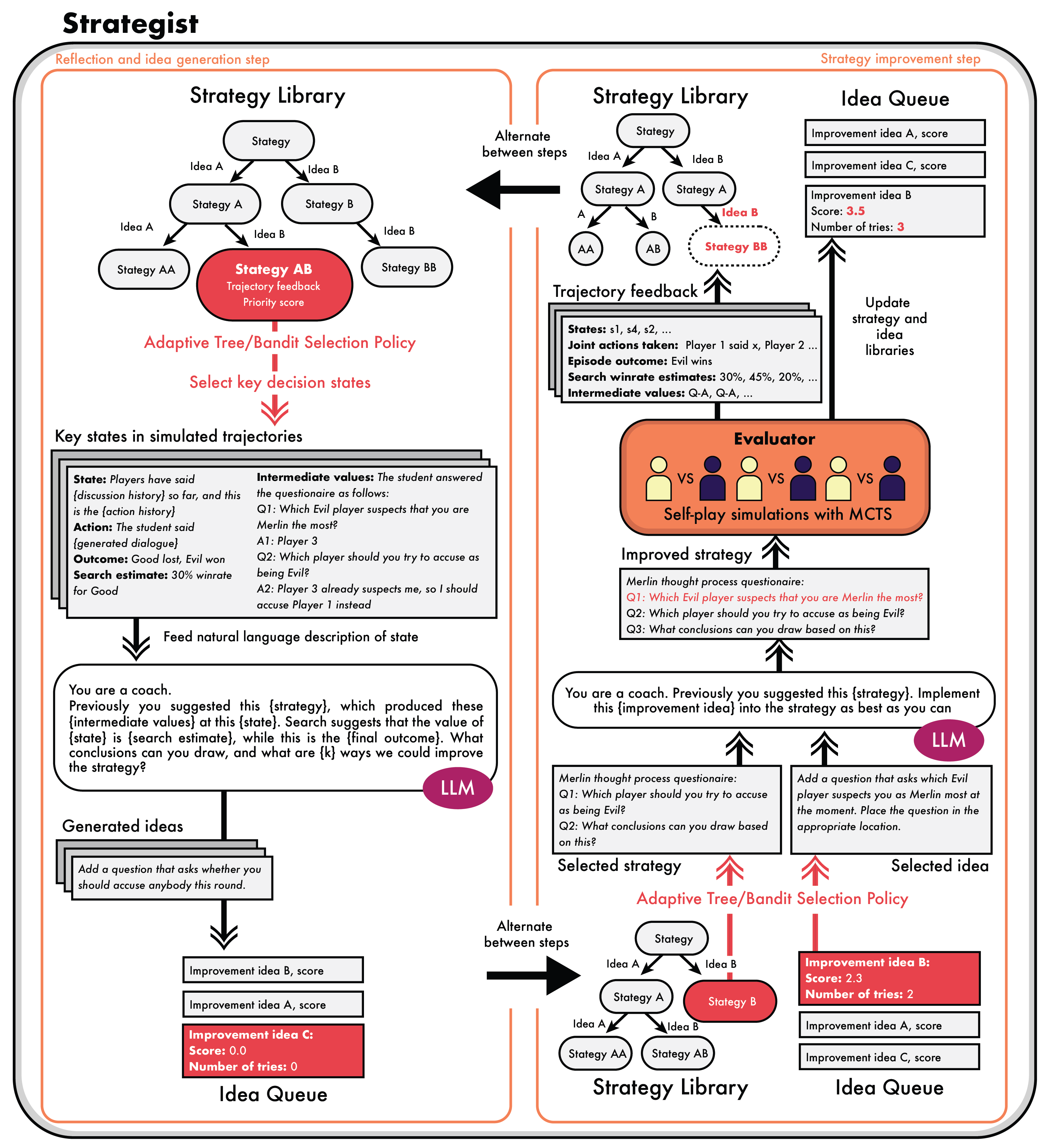
To address this researchers have introduced a new method called Strategist that utilizes LLMs to acquire new skills for playing multi-agent games through a self-improvement process. Strategist method gathers quality feedback through self-play simulations with Monte Carlo tree search and LLM-based reflection, which can then be used to learn high-level strategic skills such as how to evaluate states that guide the low-level execution.
Strategic process contains two improvement steps in each improvement cycle – the (1) reflection and idea generation step and (2) the strategy improvement step. During the idea generation step, prompt is used in LLM to reflect on simulated self-play feedback from previously evaluated strategies and generate possible improvement ideas to the strategies and add them to the idea queue. During the strategy improvement step, a strategy is selected from the strategy tree and an improvement idea from the idea queue and prompt the LLM to improve the strategy using the improvement idea. The improved strategy is then evaluated via self-play simulations, and we use the feedback and reward signals from the simulation to help guide future improvements.
The general goal in Strategist decision-making setting is to learn a good policy function in a sequential decision-making setting (generally formulated as a partially observable Markov decision game (POMDG)), which can be done by improving strategies associated with the policy function.
Strategist methods help train agents with better performance than both traditional reinforcement learning-based approaches and other LLM-based skill learning approaches in the games of Game of Pure Strategy (GOPS) and Resistance: Avalon.
Paper : https://arxiv.org/pdf/2408.10635