Traditional methods of RAG typically rely on single-round retrieval, using the LLM’s initial input to retrieve relevant information from external corpora. While this method is effective for straightforward tasks, it tends to fall short for complex multi-step tasks and long-form generation tasks. In contrast, Dynamic RAG performs multiple times of retrieval during the generation process of LLMs. It includes two steps: identifying the optimal moment to activate the retrieval module (deciding when to retrieve), and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods such as IR CoT, RETRO or IC-RALM fall short in one or both aspects.
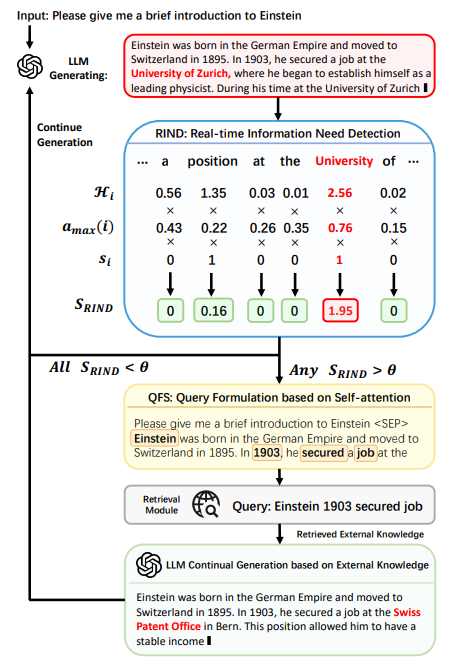
To overcome these limitations, a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation has been introduced based on the real-time Information Needs of LLMs. For the timing of retrieval (deciding when to retrieve), RIND: Real-time Information Needs Detection is used. This method refines the retrieval activation process by evaluating not only the uncertainty of each token, but also its semantic contribution and the impact on the following context. RIND begins by quantifying the uncertainty of each token generated during the LLM’s inference process. This is accomplished by recording the entropy of the token’s probability distribution across the vocabulary. For the formulation of retrieval queries, QFS: Query Formulation based on Self-attention is used, which innovates query formulation by leveraging the LLM’s self-attention across the entire context.
During evaluating the performance of DRAGIN against various baselines across four benchmark datasets: 2WikiMultihopQA, HotpotQA, StrategyQA, and IIRC. DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of underline methods. In conclusion, DRAGIN provide a lightweight RAG framework that can be incorporated into any Transformer-based LLMs without further training, fine-tuning, or prompt engineering.