State-space models (SSMs) have recently demonstrated competitive performance to transformers at large-scale language modeling benchmarks while achieving linear time and memory complexity as a function of sequence length. Mamba, a recently released SSM model, shows impressive performance in both language modeling and long sequence processing tasks. Simultaneously, mixture-of-expert (MoE) models have shown remarkable performance while significantly reducing the compute and latency costs of inference at the expense of a larger memory footprint.
So why not combine Mamba with MoE. Well that is what this paper has explored with BlackMamba, a novel architecture that combines the Mamba SSM with MoE to obtain the benefits of both. This Mamba-MoE architecture have the following improvements over a dense transformer:
Mamba: Linear computational complexity with respect to input sequence length for both training and inference. Autoregressive generation in constant time and memory.
MoE: Inference latency and training FLOPs of the equivalent smaller dense base model, while preserving model quality close to an equi-parameter dense model.
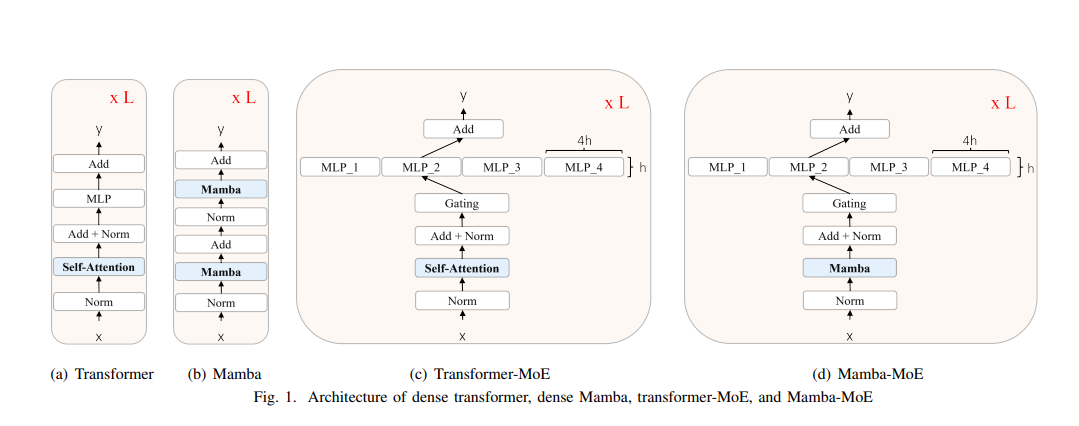
BlackMamba architecture simply replaces both the MLP layer in a transformer with an expert layer, and the attention layer with a mamba SSM layer. Further, it used the SwiGLU activation function for the expert MLPs. For the expert router, it used top-1 routing with a Sinkhorn routing function to load-balance between experts. It utilized a novel custom version of the Sinkhorn algorithm which converges substantially faster than vanilla Sinkhorn. Model was trained using Megatron-LM distributed training framework and was trained in bf16 precision on 300B tokens on custom dataset both 340M/1.5B and 630M/2.8B models .
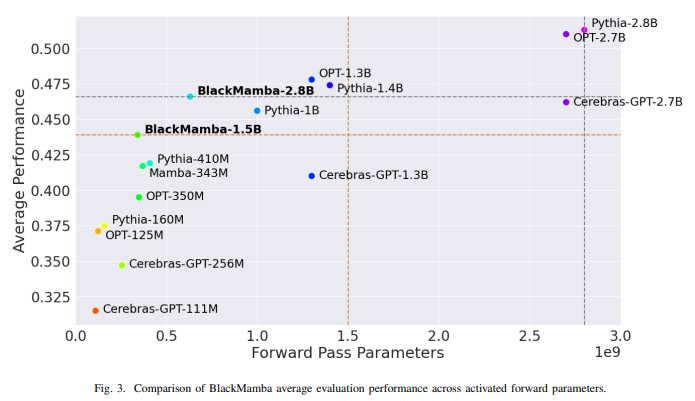
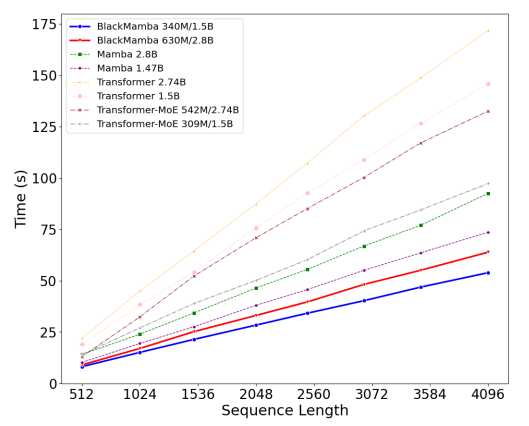
BlackMamba performs competitively against both Mamba and transformer baselines, and outperforms in inference and training FLOPs. BlackMamba inherits and combines both of the benefits of SSM and MoE architectures, combining linear-complexity generation from SSM with cheap and fast inference from MoE. Moreover, BlackMamba shows that it is capable of rapid generation with both linear time and memory cost.