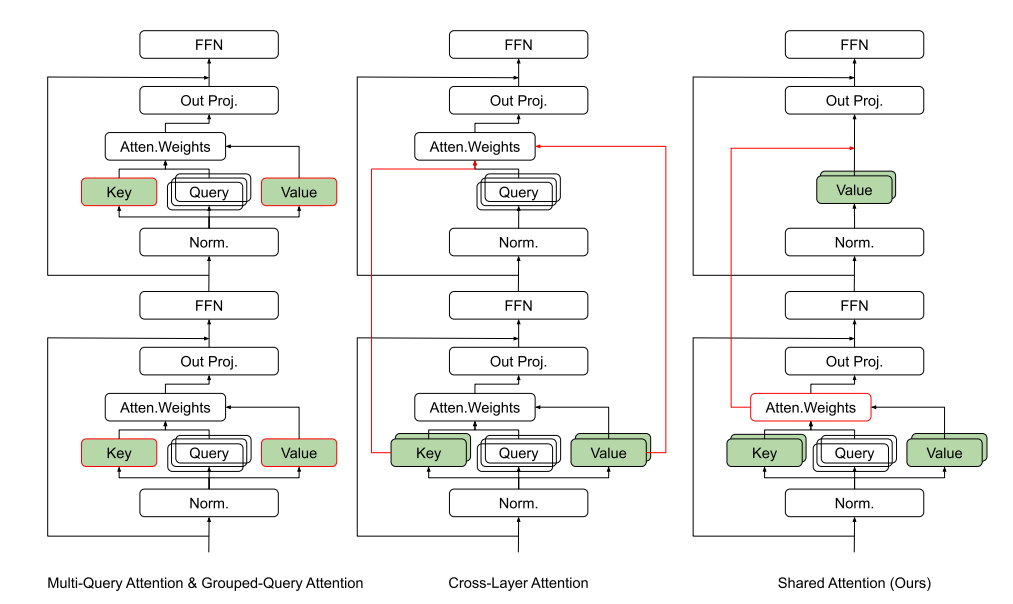
The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models such as Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) made strides in reducing the key-value (KV) cache size by sharing keys and values across multiple heads within a layer. More recently, Cross-Layer Attention (CLA) has extended this concept by sharing keys and values across adjacent layers, further reducing memory requirements without substantially impacting model performance, while powerful these Attention mechanism still require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers.
To address this researchers have introduced a novel method called Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, SA utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference.
The MQA and GQA methods share the Key and Value caches with the Query within the same layer to reduce memory usage. The CLA method extends this by sharing the Key and Value caches across different layers. Shared Attention, advances this concept further by sharing the attention weights across multiple layers.
Empirically implementing SA across various LLMs (Llama-7B and Llama-8B) results in minimal accuracy loss on standard benchmarks including GLUE and MMLU. Further, It was found that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Paper : https://arxiv.org/pdf/2407.12866