Self-Play Fine-Tuning (SPIN) is a new fine-tuning method to improve large language models (LLMs) without needing additional human-annotated data.
The key idea is to use a self-play mechanism where the LLM plays against itself. Specifically, the LLM from the previous iteration generates synthetic responses. The new LLM being trained tries to discern between the synthetic responses and real human responses. This iterates, with the new LLM becoming the synthetic data generator for the next iteration.
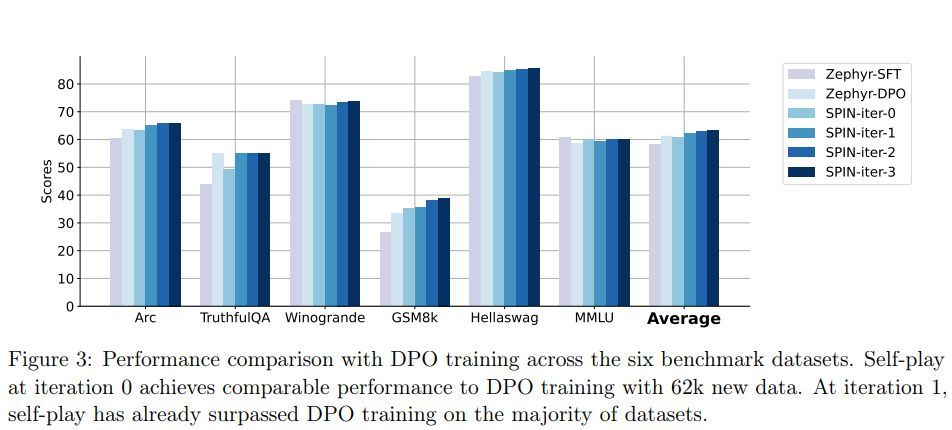
The method is shown to significantly enhance LLMs’ performance on a variety of benchmarks: - On the HuggingFace Open LLM Leaderboard, SPIN improves the average score from 58.14 to 63.16 with over 10% gains on some datasets. - On the MT-Bench benchmark, the score improves from 5.94 to 6.78. - The gains match or exceed models trained with additional human preference data.
Theoretically, it is proven that SPIN converges when the LLM distribution aligns perfectly with the real data distribution.
Overall, the self-play approach enables iterative improvement of LLMs without needing extra human feedback or data, converting weak models to strong models by unleashing the full potential of existing labeled data.