Recently small-scale visual language models performance have come in par with its larger-scale counterparts. Models such as LLaVAPhi [47], which combines the open source multi-modal model LLaVA-1.5 and the open source small language model Phi-2(2.7B) have shown great promise to improve multi-modal model resource efficiency. However, despite the encouraging advancements made in the realm of visual language models, the pursuit of a genuinely optimal harmony between performance and efficiency remains an active and ongoing challenge.
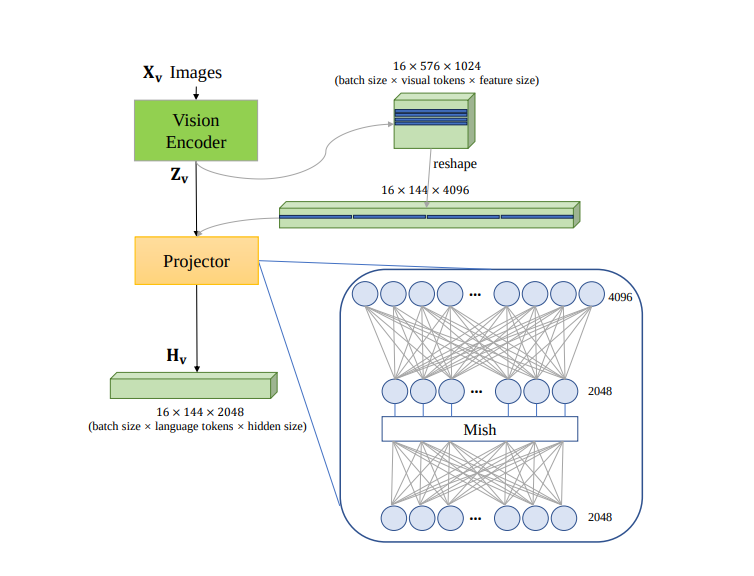
To address this researchers have introduced Xmodel-VLM, a cutting-edge multimodal vision language model designed for efficient deployment on consumer GPU servers. The architecture of Xmodel-VLM, closely mirrors that of LLaVA-1.5. It consists of three key components: (1) a vision encoder : a pre-trained CLIP ViT-L/14 with a resolution of 336×336 (2) a lightweight language model (LLM) : an lightweight language model Xmodel-LM 1.1B from scratch based on LLaVA architecture. (3) a projector responsible for aligning the visual and textual spaces. It utilizes a two-layer MLP to strengthen the link between the vision encoder and LLM, employing the Mish activation function. This innovative projector, known as XDP, acts as both a connection enhancer and a downsampling mechanism, reducing visual tokens by 75%. XDP’s design emphasizes simplicity and effectiveness.
The training of Xmodel_VLM occurs in two main stages: Stage I - Pre-training: In this stage, the vision encoder is kept frozen The XDP projector and the LLM (Language Model) are both learnable. Stage II - Multi-task Training: Similar to Stage I, the vision encoder remains frozen, while both the XDP projector and the LLM are learnable. This stage involves training the model on multiple tasks simultaneously.
During evaluation across a variety of datasets: VizWiz, SQAI, VQA, POPE, GQA, MMB, MMBCN, MMVet and MME Xmodel-VLM 1.1B demonstrates competitive performance against Qwen-7B, LLaMA-7B and Vicuna-13B despite having small model parameter.
Paper : https://lnkd.in/gBK9W-2H