Proprietary LMs such as GPT-4 model-based evaluation have emerged as a scalable solution for assessing LM-generated text. However, concerns related to transparency, controllability, and affordability these proprietary LMs have led to the development of open source LMs specialized in evaluations. But, these open source evaluator language models fall short in two key areas: they often diverge from human scores and lack flexibility to perform common evaluation methods like direct assessment and pairwise ranking. They also lack the ability to evaluate based on custom criteria, focusing on general attributes instead.
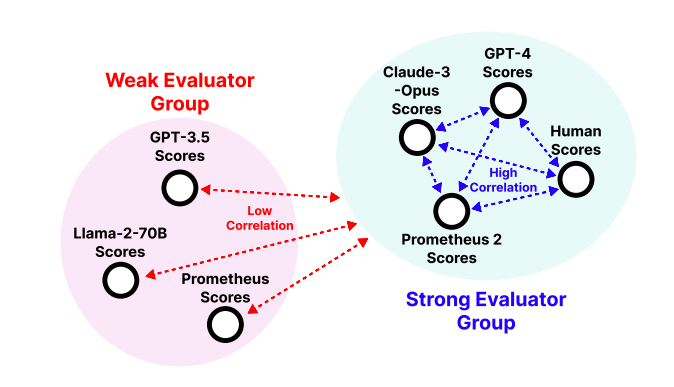
To address these issues, researchers have introduced Prometheus 2, a more powerful evaluator LM that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. To achieve this, researchers have merged the weights of two evaluator LMs trained separately on direct assessment and pairwise ranking formats and this weight merging have yield an evaluator LM that not only works in both formats, but also outperforms evaluator LMs that are jointly trained or only trained on a single format.
For Prometheus 2 researchers use Mistral-7B and Mixtral8x7B as base models, and merge the weights of evaluator LMs separately trained on the FEEDBACK COLLECTION, a direct assessment feedback dataset, and the PREFERENCE COLLECTION dataset, a new fine-grained pairwise ranking feedback dataset that builds on the FEEDBACK COLLECTION, to obtain resulting models, PROMETHEUS 2 (7B & 8x7B).
On four direct assessment benchmarks (Vicuna Bench, MT Bench, FLASK, Feedback Bench), the PROMETHEUS 2 models demonstrate the highest correlation with both human evaluators and proprietary LM-based judges compared to existing open evaluator LMs, with the Pearson correlation surpassing other baselines by 0.2 units across all datasets. Similarly, on four pairwise ranking benchmarks (HHH Alignment, MT Bench Human Judgment, Auto-J Eval, Preference Bench), the PROMETHEUS 2 models show the highest agreement with human evaluators among all the open evaluator LMs we tested, reducing the performance gap with GPT-4 in half.
Paper : https://arxiv.org/pdf/2405.01535