Reinforcement Learning from Human Feedback (RLHF) is one of the most popular methods to align Pretrained Large Language Models (LLMs) with human preferences. It involves fitting a reward model (RM) on human preference data, and then uses this RM to tune the parameters of the LLM using Reinforcement Learning (RL). Typically, there are 2 model training processes as part of the RLHF process: reward model training, and reinforcement learning. However, the complexity and computational cost of the RLHF training process has hindered its adoption.
So is there any way to make RLHF more efficient and accessible ?
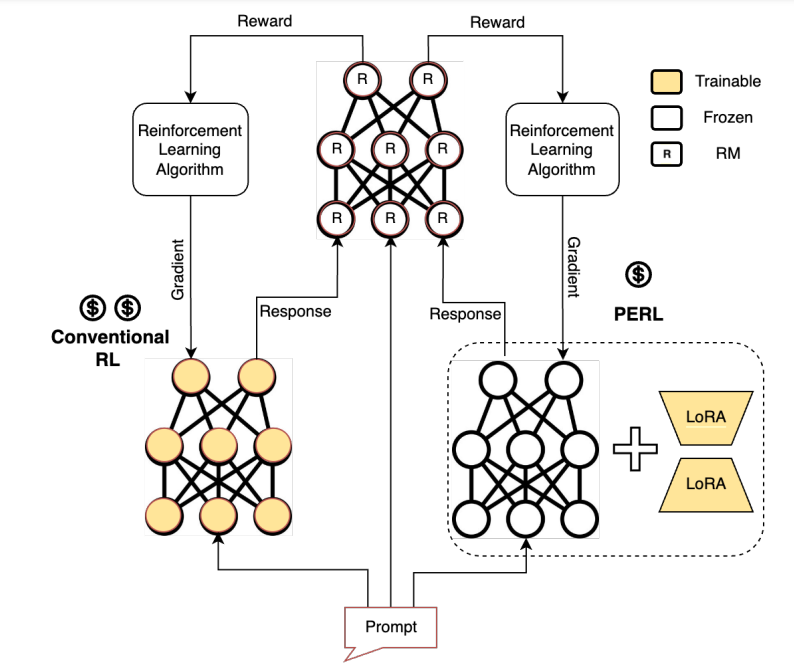
That is what researchers from Google have solved by using Parameter Efficient Reinforcement Learning (PERL), in which LoRA is used to perform reward model training and reinforcement learning.
During reward model training in PERL, LoRA adapters are attached to each attention projection matrix and trained while keeping the language model backbone frozen. These trained adapters are saved and combined with the projection matrices during inference, resulting in a reward model equivalent to a non-LoRA one.
In the PERL reinforcement learning loop, language models with LoRA adapters serve as policy models. LoRA adapters are attached to each attention projection matrix, with only these adapters being trained while the language model backbone remains frozen. Training involves policy gradient computation on reward scores, along with KL regularization with the anchor policy. The memory required for training, primarily due to modern optimizers like Adam or Adafactor, is reduced significantly by PERL’s reduction in trainable parameters.
During extensive experiments on various datasets (Reddit TL;DR, BOLT English SMS/Chat dataset, Anthropic’s Helpfulness and Harmlessness dataset and Stanford Human Preferences Dataset), PERL achieves comparable results to conventional RLHF, for which all the model parameters are tuned, while reducing memory usage by approx 50%, and speeding up the training by up to 90% for the Reward Model training, and more modest memory savings of 20%, and speed-up of 10% in the RL loop.