Mastering spatiotemporal representation is one of the key areas in any video understanding task. However there usually are two challenges associated with it: (1) the large spatiotemporal redundancy within short video clips, and (2) the complex spatiotemporal dependencies among long contexts. Models such as 3D-CNN + Video transformer, S4, RMKV and RetNet tried to resolve above challenges associated with spatio-temporal but none has been successful so far.
So can Mamba work well for video understanding?
That’s what researchers have tried to address with VideoMamba, a purely SSM-based model tailored for video understanding. VideoMamba harmoniously merges the strengths of convolution and attention in vanilla ViT style. It offers a linear-complexity method for dynamic spatiotemporal context modeling, ideal for high-resolution long videos.
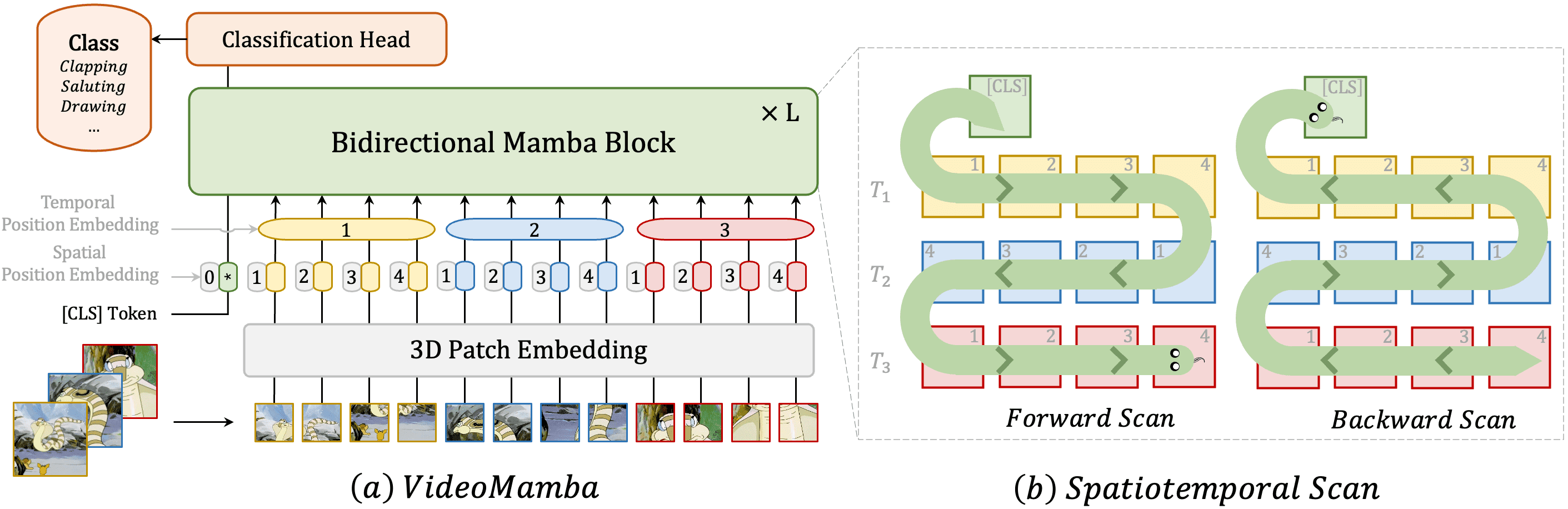
Framework of VideoMamba strictly follow the architecture of vanilla ViT and adapt the bidirectional mamba block (B-Mamba) for 3D video sequences. Bidirectional Mamba (B-Mamba) block, adapts bidirectional sequence modeling for vision-specific applications. This block processes flattened visual sequences through simultaneous forward and backward SSMs, enhancing its capacity for spatially-aware processing. To apply the B-Mamba layer for spatiotemporal input, VideoMamba extends the original 2D scan into different Spatial-First bidirectional 3D scan, organizing spatial tokens by location then stacking them frame by frame.
Extensive evaluations reveal VideoMamba’s four core abilities: (1) Scalability in the visual domain without extensive dataset pretraining, thanks to a novel self-distillation technique; (2) Sensitivity for recognizing short-term actions even with fine-grained motion differences; (3) Superiority in long-term video understanding, showcasing significant advancements over traditional feature-based models; and (4) Compatibility with other modalities, demonstrating robustness in multi-modal contexts. Through these distinct advantages, VideoMamba sets a new benchmark for video understanding, offering a scalable and efficient solution for comprehensive video understanding.
Paper : https://lnkd.in/g8quHTqR
Code : https://lnkd.in/gFN3sbZ5
Model : https://lnkd.in/gH85xRkz