Text-to-SQL has been one of the shout-out use cases in AI application development especially with close source LLM such as GPT4. However, the adoption of closed source LLMs introduces concerns pertaining to issues of openness, privacy, and substantial costs.
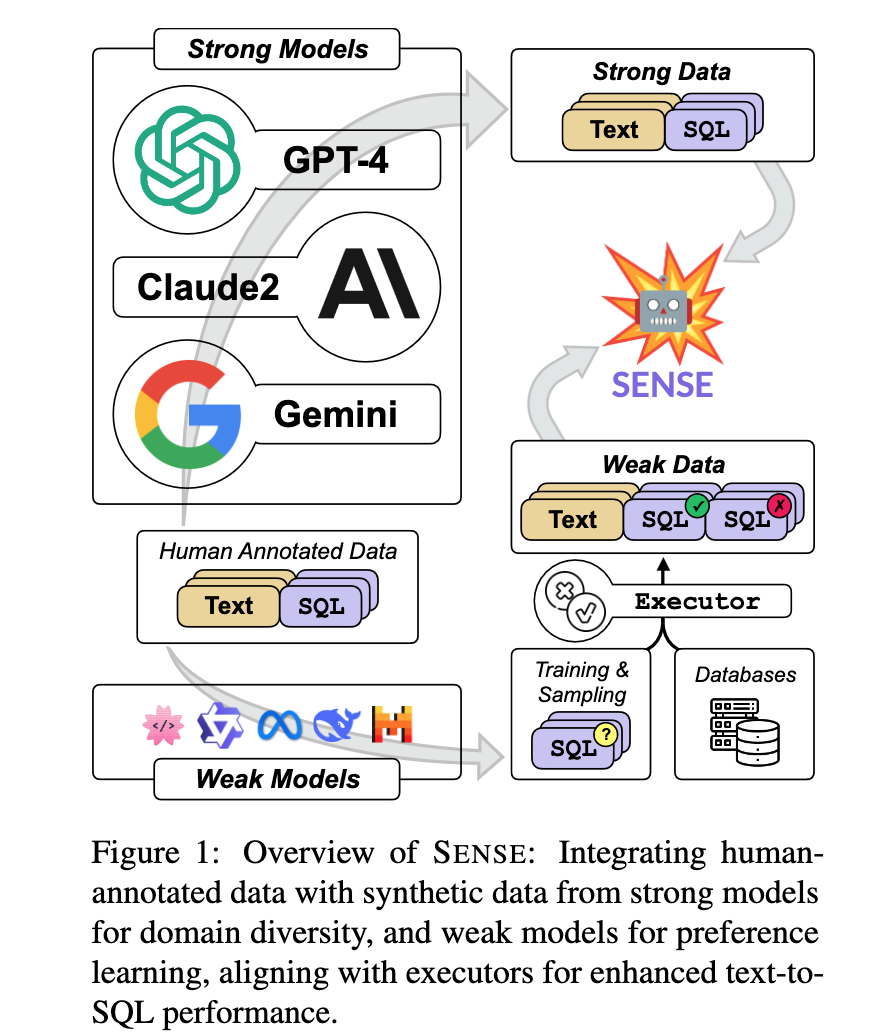
Developing specialized text-to-SQL models built upon open-source LLMs remains a challenge due to the high cost of achieving text-to-SQL data, which relies on manual expert annotation. To overcome this, researchers have introduced a synthetic data approach that amalgamates strong data generated by larger, more potent models (strong models) with weak data produced by smaller, less well aligned models (weak models). This approach contributes to the improvement of domain generalization in text-to-SQL models and investigates the potential of weak data supervision through preference learning. Further, researchers have utilized the synthetic data approach for instruction tuning on open-source LLMs, yielding SENSE.
SENSE, Integrating human annotated data with synthetic data from strong models for domain diversity, and weak models for preference learning, aligning with executors for enhanced text-toSQL performance.
Extensive experiments demonstrate that SENSE achieves state-of-the-art performance on the SPIDER and BIRD benchmarks, thereby mitigating the performance disparity between open-source models and the methods derived from closed-source models.
Paper : https://arxiv.org/pdf/2408.03256