Large language models have shown promising results in arithmetic and symbolic reasoning by expressing intermediate reasoning in text as a chain of thought, yet struggle to extend this capability to answer text queries that are easily solved by visual reasoning, even with extensive multimodal pretraining.
Such visual reasoning tasks demand visuals and one can leverage the abilities of multimodal large language models (MLLMs) to achieve this. By providing MLLMs the ability to create and reason with explicit visuals – like a whiteboard showing intermediate thoughts – unlocks capabilities resembling visual thinking.
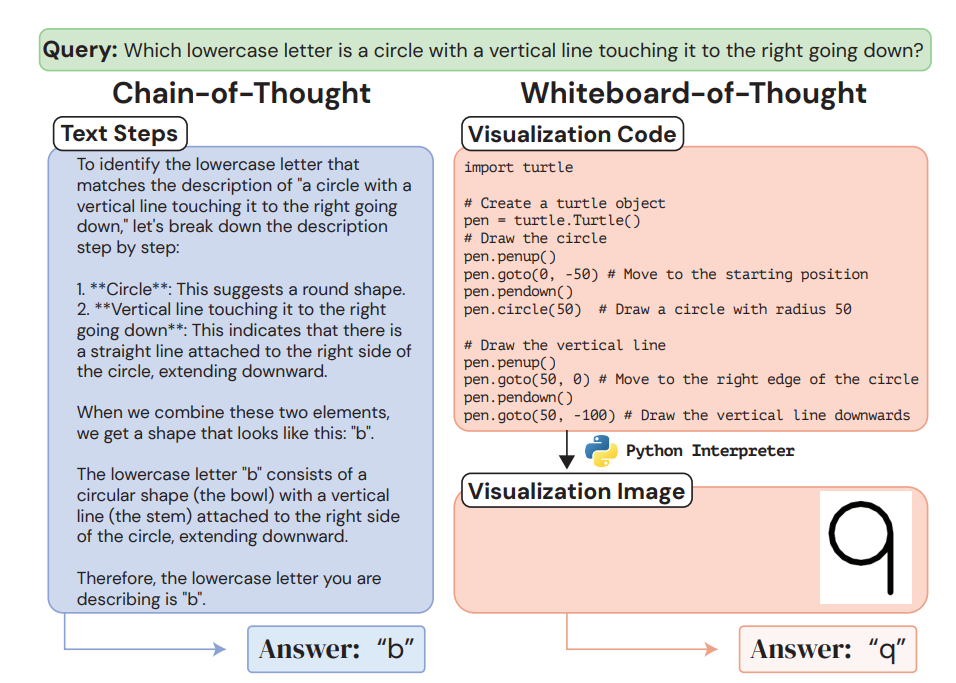
On the same key idea researcher have introduced whiteboard-of-thought (WoT)’: a novel prompting method, which provide MLLMs with a metaphorical ‘whiteboard’ to draw out the results of intermediate reasoning steps as images, then prompt them to use their visual input capabilities to produce answers or perform further reasoning from the visuals made by the model itself. It is interesting to note that WoT leveraging models’ existing ability to write code with visual graphics libraries such as Turtle and Matplotlib proves sufficient to create visuals useful for solving visual reasoning tasks without requiring a single example.
In general WoT provides the MLLM with the input prompt - You write code to create visualizations using the {Matplotlib/Turtle} library in Python, which the user will run and provide as images. Do NOT produce a final answer to the query until considering the visualization - along with the query. The model then decides what visualization code to write based on the query. The resulting code is then passed to a runtime environment to render it in image form. In this case, one can use the Python interpreter with the previously mentioned visualization libraries.
This simple approach shows state-of-the-art results on four difficult natural language tasks that involve visual and spatial reasoning. Multiple settings were identified where GPT-4o using chain-of-thought fails dramatically, including more than one where it achieves 0% accuracy, while whiteboard-of-thought enables up to 92% accuracy in these same settings.
Paper : https://arxiv.org/pdf/2406.14562