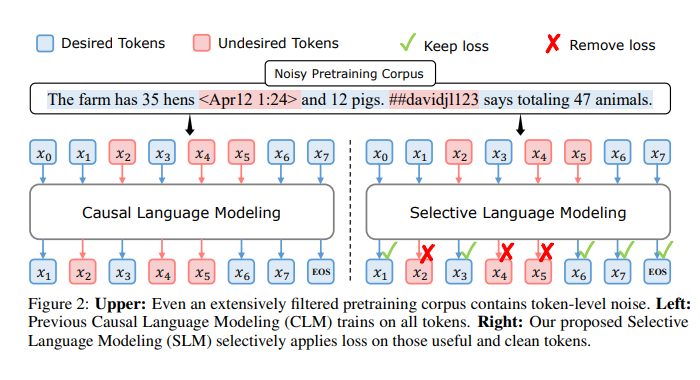
High quality training data sets are crucial to boost LLMs performance. Various data filtering techniques such as heuristics and classifiers are being utilized to select such training dataset. However, despite thorough document-level filtering, high-quality datasets still contain many noisy tokens that can negatively affect training.
Further, common corpus at the token level may include undesirable content like hallucinations or highly ambiguous tokens that are hard to predict. Applying the same loss to all tokens can result in wasted computation on non-beneficial tokens, possibly limiting LLM’s potential to merely mediocre intelligence.
So are all tokens in a corpus equally important for language model training ?
Apparently not, researchers have found two groups of tokens exist during training : “easy tokens” that are already learned, and “hard tokens” that exhibit variable losses and resist convergence. These tokens can lead to numerous ineffective gradient updates. To explain this researchers have introduced a new language model called RHO-1. Unlike traditional LMs that learn to predict every next token in a corpus, RHO-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that are aligned with the desired distribution. The approach involved
- Train a reference language model on high-quality corpora.
- Use above reference model to score each token in a corpus using its loss
- Finally, train a language model only on those tokens that exhibit a high excess loss between the reference and the training model.
During evaluation, RHO-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively — matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when pretraining on 80B general tokens, RHO-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.