Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, alignment can be challenging, especially for the largest and most competent LLMs which often require a large corpus of (un)acceptable behavior (on the order of ≈ 1K samples.
Is it possible to align an LLM to a specific setting by leveraging a very small number (< 10) of demonstrations as feedback ?
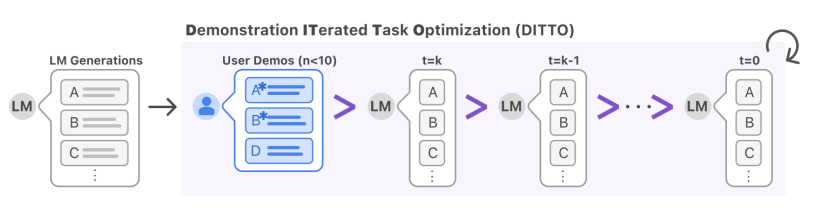
Well that is what researchers from Stanford have addressed with Demonstration ITerated Task Optimization (DITTO), a framework for aligning LLMs to specific settings by providing a small number of demonstrations be drawn from a user’s existing interaction logs, or from direct edits made to LLM outputs. DITTO, scaffolds a handful of these demonstrations (< 10) into a substantial dataset of preference comparisons, by treating users’ demonstrations as preferred over model output from both the original LLM and models’ earlier training iterations. This augmented dataset of demonstration-grounded comparisons can then be used to update the language model using an alignment algorithm like DPO.
In general, DITTO iteratively aligns LLMs to demonstrated behavior. When a user supplies demonstrations (through edits to a model’s output, past preferred interaction history, or writing examples from scratch), DITTO treats these demonstrations as preferred to all model behavior, including earlier iterations of the trained model. Using demonstrations as feedback allows for cheap generation of online comparison data and enables few-shot alignment with just a handful of samples.
DITTO’s ability was evaluated to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts. Additionally, a user study was conducted soliciting a range of demonstrations from participants (N = 16). Across these benchmarks and user study, it was found that win-rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. By using demonstrations as feedback directly, DITTO offers a novel method for effective customization of LLMs.
Paper : https://arxiv.org/pdf/2406.00888