The availability of Huggingface PEFT modules has made it cheap and easy to modularly adapt a given pre-trained model to a specific task or domain. In the meantime, extremely large-scale language models (LLMs) are now being treated as “general-purpose” and often exhibit strong zero-shot generalization. Relying on zero-shot generalization stands in stark contrast to the aforementioned approach of training specialized models for each task such as PEFT.
So can we leverage a large collection of specialized modules to improve zero-shot generalization of a base language model ?
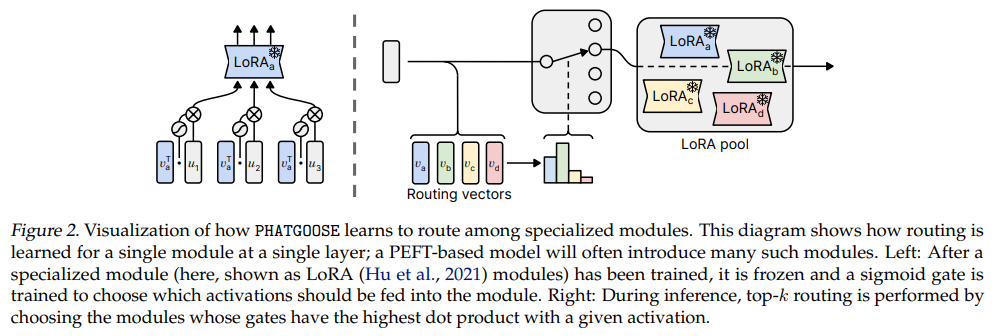
That’s what this paper has tried to address with PHATGOOSE : Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts, a post-hoc method that enables zero-shot generalization among specialized models. PHATGOOSE recycles PEFT modules by introducing an additional computationally inexpensive step after training the PEFT-based model itself. Specifically, the entire model (including the newly introduced PEFT modules) is frozen and a per-module gate is trained. This gate (whose parameters are shared across sequence positions) comprises a linear layer followed by a sigmoid nonlinearity that determines whether the activation at a given sequence position should be fed into the module or not. Training this gate only requires a small amount of additional compute compared to performing PEFT. The gates for every module across specialized models are then combined to determine how to route different tokens to different modules during inference using a standard “top-k” routing strategy.
To test the effectiveness of PHATGOOSE, T5 family models were used to improve zero-shot generalization on standard benchmarks. Notably, it was found that PHATGOOSE not only outperforms prior methods involving merging experts or retrieving a single expert but can also outperform explicit multitask training in some cases. In qualitative analysis, it was found that PHATGOOSE uses a diverse set of modules to perform a given task, thereby combining abilities from multiple specialized models and, in some cases, producing better performance than the single best-performing expert model. Overall, this work sets the groundwork for a promising new framework for the decentralized development of generalist AI systems.
Paper : https://arxiv.org/pdf/2402.05859.pdf
Github : https://github.com/r-three/phatgoose