The computational challenges of LLM inference remain a significant barrier to their widespread deployment, especially as context lengths continue to increase. Existing efficient methods for long-context LLMs have focused on KV-cache compression, static sparse attention (e.g., model compression, SSM, linear attention), or distributed serving. However, these methods struggle to achieve acceptable latency for million-token level prompts with low cost and a single A100 GPU.
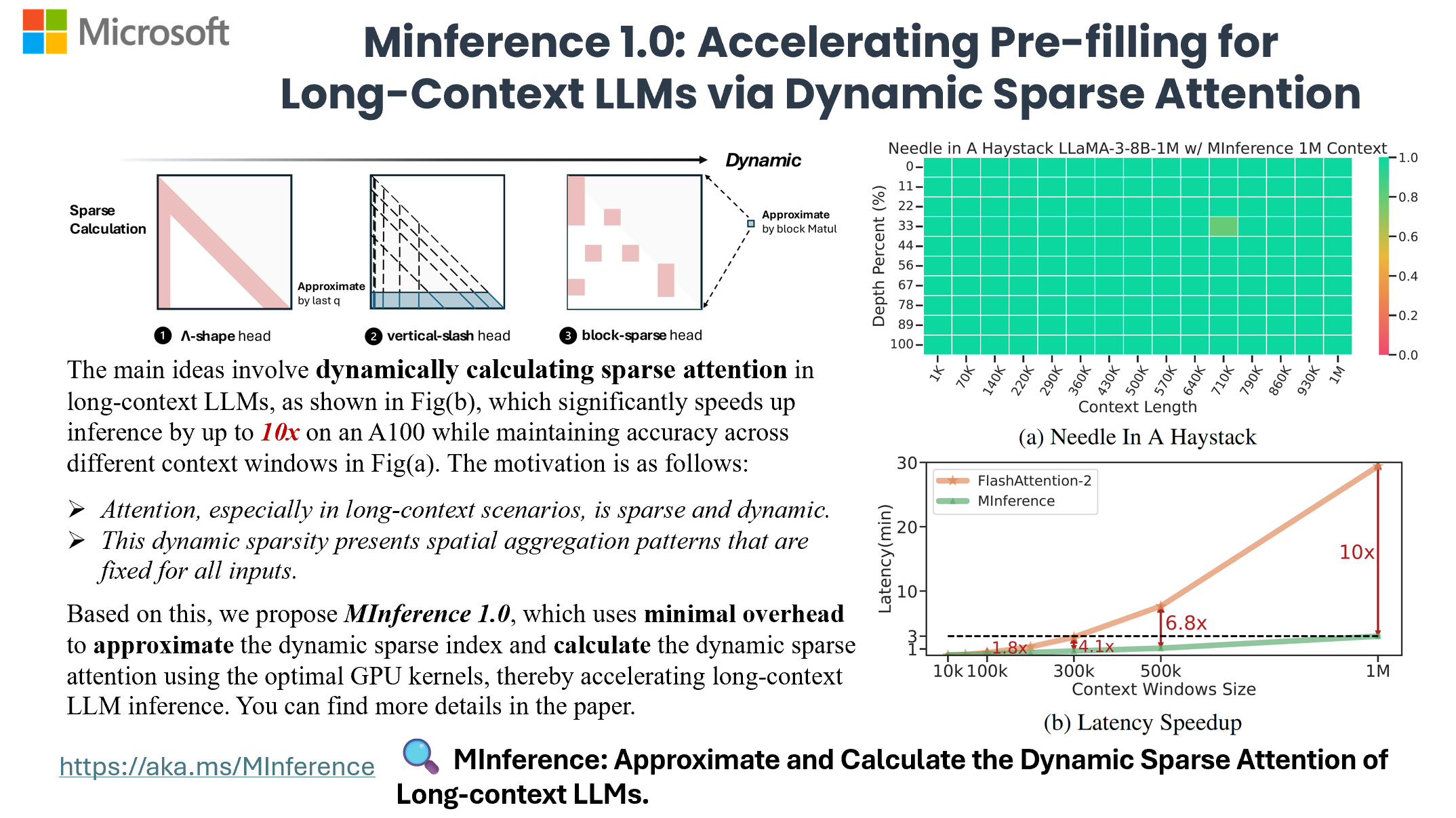
To address this gap, researchers from Microsoft have introduced MInference, a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Attention, especially in long-context scenarios, is sparse and dynamic, i.e., the sparse patterns are largely different across inputs. This dynamic sparsity presents three unique spatial aggregation patterns that persist for all inputs: A-shape, Vertical-Slash, and Block-Sparse—that can be leveraged for efficient sparse computation on GPUs.
MInference is a training-free efficient method for the pre-filling stage of long-context LLMs based on dynamic sparse attention. Specifically, leverage three types of static spatial aggregation patterns of dynamic sparse attention: A-shape, Vertical-Slash, and Block-Sparse. MInference first determines the optimal dynamic sparse pattern for each head offline using the Kernel-Aware Sparse Pattern Search algorithm. During inference, it dynamically approximates the dynamic sparse indices based on the head’s pattern. Finally, efficient dynamic sparse attention is computed using optimized GPU kernel.
For example, with the Vertical-Slash pattern, first the attention calculation between the last Q (Query vector) and K (Key vector) is used to estimate the optimal indices of vertical lines and slash lines. Then, the dynamic sparse compiler PIT and Triton are utilized to construct the Vertical-Slash FlashAttention kernel, accelerating the attention computation. For the A-shape, Vertical-Slash, and Block-Sparse patterns, first the mean pooling of Q and K in attention calculations is used. By leveraging the commutative property of mean pooling and MatMul, the block-spa is estimated. Then, Triton construct the Block-Sparse FlashAttention kernel, accelerating the attention computation.
By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, Yi-200K, GLM-4-1M, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy.
Paper : https://arxiv.org/pdf/2407.02490