In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. MMLU includes a broad range of exam questions from 57 subjects across STEM, the humanities, the social sciences, etc. However, the rapid progress of current LLMs has quickly led to performance saturation on MMLU. Since GPT-4 achieved 86.4% in March 2023, there has not been any significant progress on the benchmark. Even GPT-4o achieved 1% improvement on MMLU to obtain 87.4%.
This is due to the structure of the Multiple-Choice Machine Reading Comprehension (MMLU) dataset which provides only three options, potentially allowing LLMs to guess answers without understanding. Further, MMLU questions are often more about knowledge recall than reasoning, especially in STEM subjects, making them easier. Finally, some questions are unanswerable or wrongly annotated, limiting the dataset’s usefulness and affecting model performance.
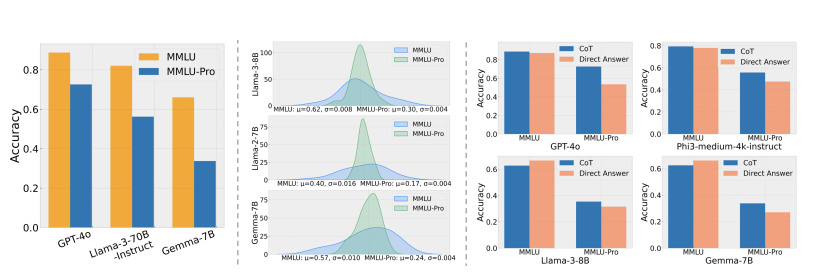
To address these challenges researchers have introduced MMLU-Pro: a comprehensive benchmark designed for proficient-level multi-discipline language understanding and reasoning. MMLU-Pro spans 14 diverse domains including mathematics, physics, chemistry, law, engineering, psychology, and health, encompassing over 12,000 questions and thus meeting the breadth requirement. MMLUPro is distinctive from MMLU in the following aspects: * 1. MMLU-Pro has ten options, which contain 3x more distractors than MMLU. By increasing the distractor numbers, it significantly reduces the probability of correct guess by chance to boost the benchmark’s difficulty and robustness. * 2. MMLU-Pro increases the portion of challenging college-level exam problems. These questions require LLM to perform deliberate reasoning in different domains to derive the final answer. * 3. MLU-Pro integrates two rounds of expert reviews to reduce the noise of the dataset. The first round is based on expert verification. In the second round, it utilizes the SoTA LLMs to identify potential errors and employ annotators to perform more targeted verification.
Experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. In conclusion, MMLU-Pro is a more discriminative benchmark to better track progress of both present and upcoming LLMs.
Paper : https://arxiv.org/pdf/2406.01574