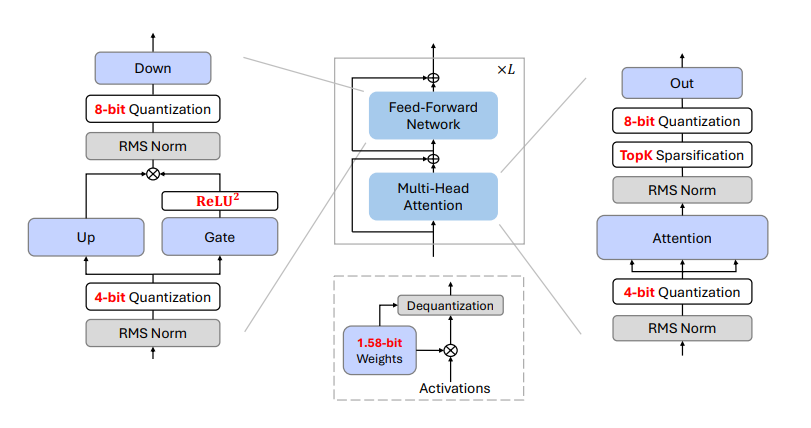
Recent research on the 1-bit Large Language Models (LLMs), such as BitNet b1.58, presents a promising direction for reducing the inference cost of LLMs while maintaining their performance. This is mainly achieved by utilizing activation sparsity, which reduces the inference FLOPs and the I/O of weight by pruning the activation entries with smaller magnitudes. In addition to sparsification, the activation quantization approach is also used to accelerate the matrix multiplication.
Continuing on this work researchers have introduced BitNet a4.8, a hybrid quantization and sparsification strategy that enables 4-bit activations for 1-bit LLMs. BitNet a4.8 employs a hybrid quantization and sparsification strategy to mitigate the quantization errors introduced by the outlier channels. Specifically, BitNet a4.8 employs 4-bit activations for the inputs to attention and FFN, while utilizing sparsification with 8 bits for intermediate states. To improve the training efficiency, BitNet a4.8 is trained from 8-bit to 4-bit activations with a two-stage recipe, which requires only a few training tokens to adapt BitNet b1.58 to the low-bit activations at the end of training.
Extensive experiments demonstrate that BitNet a4.8 achieves performance comparable to BitNet b1.58 with equivalent training costs, while being faster in inference with enabling 4-bit (INT4/FP4) kernels. Additionally, BitNet a4.8 activates only 55% of parameters and supports 3-bit KV cache, further enhancing the efficiency of large-scale LLM deployment and inference.
Paper : https://arxiv.org/pdf/2411.04965