Recently, Long context LLMs have been pinnacle in further advancement of generative ai in various fields. Now researchers have introduced the MiniMax-01 series long context LLMs, including MiniMax-Text-01 and MiniMax-VL-01.
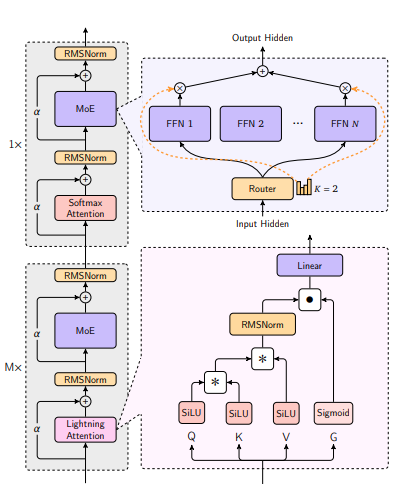
MiniMax-Text-01 is a powerful language model boasting 456 billion total parameters, with 45.9 billion activated per token. To unlock its long-context capabilities, it adopts a hybrid architecture integrating Lightning Attention, Softmax Attention, and Mixture-of-Experts (MoE). Leveraging advanced parallel strategies like Linear Attention Sequence Parallelism Plus (LASP+), varlen ring attention, and Expert Tensor Parallel (ETP), its training context length extends to 1 million tokens, and it can handle up to 4 million tokens during inference.
Building on MiniMax-Text-01’s prowess, researchers have also developed MiniMax-VL-01 for enhanced visual capabilities. It uses the “ViT-MLP-LLM” framework common in multimodal LLMs. It is initialized and trained using three key components: a 303-million-parameter Vision Transformer (ViT) for visual encoding, a randomly initialized two-layer MLP projector for image adaptation, and MiniMax-Text-01 as the base LLM. This model features a dynamic resolution mechanism. Input images are resized according to a pre-set grid, with resolutions ranging from 336×336 to 2016×2016, while maintaining a 336×336 thumbnail. The resized images are split into non - overlapping patches of the same size. These patches and the thumbnail are encoded separately and then combined to form a full image representation. As a result, MiniMax-VL-01 has achieved top-level performance on multimodal leaderboards, demonstrating its edge in complex multimodal tasks.
Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering a 20-32 times longer context window.
Paper : MiniMax-01: Scaling Foundation Models with Lightning Attention