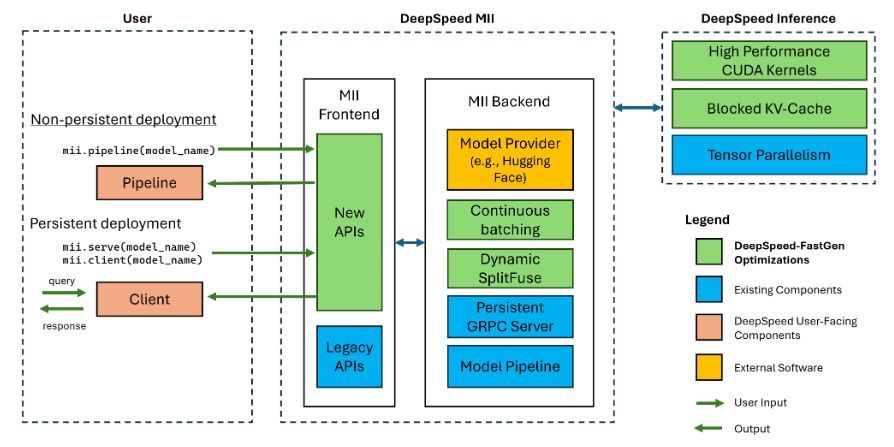
Recently Microsoft DeepSpeed launched DeepSpeed-FastGen LLM serving framework, which offers up to 2.3x higher effective throughput compared to state-of-the-art systems like vLLM. DeepSpeed-FastGen leverages the combination of DeepSpeed-MII and DeepSpeed-Inference to provide an easy-to-use serving system.
DeepSpeed-FastGen is built to leverage continuous batching and non-contiguous KV caches to enable increased occupancy and higher responsivity for serving LLMs in the data center, similar to existing frameworks such as TRT-LLM, TGI, and vLLM. In order to achieve a new level of performance, DeepSpeed-FastGen introduces SplitFuse which leverages dynamic prompt and generation decomposition and unification to further improve continuous batching and system throughput.
During experiment, DeepSpeed-FastGen outperforms vLLM in both throughput and latency. On Llama-2 70B with 4 A100x80GB, DeepSpeed-FastGen demonstrates up to 2x higher throughput (1.36 rps vs. 0.67 rps) at identical latency (9 seconds) or up to 50% latency reduction (7 seconds vs. 14 seconds) while achieving the same throughput (1.2 rps).
Supported models : LLaMA and LLaMA-2, Mistral, OPT, Falcon, Mixtral, Phi-2, Qwen