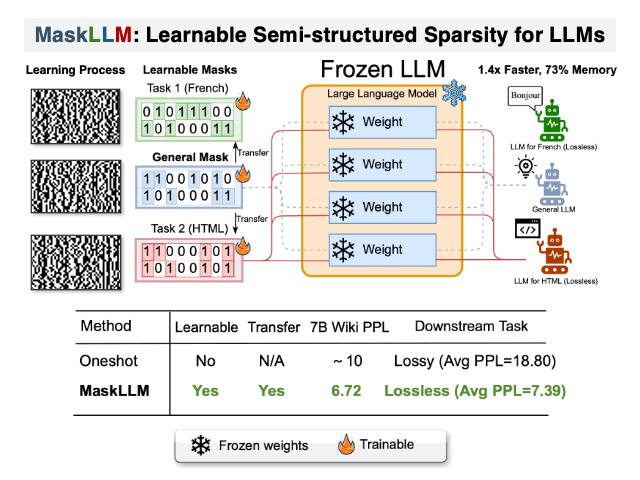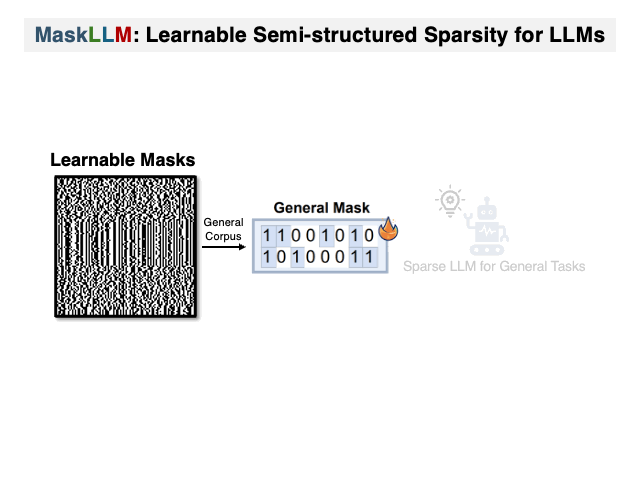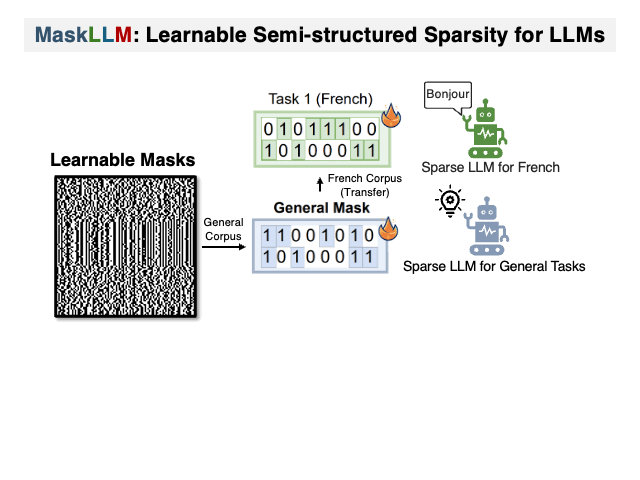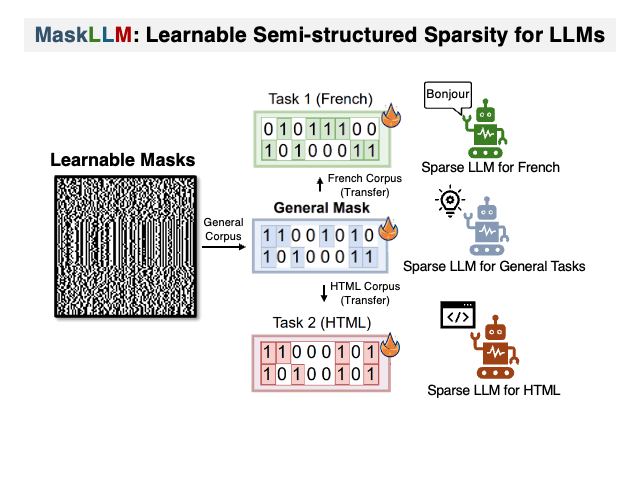
Large Language Models (LLMs) have demonstrated remarkable effectiveness across a diverse range of tasks. However, LLMs are usually distinguished by their massive parameter counts, which typically result in significant redundancy. One effective and practical approach to address this issue is semi-structured pruning, which introduces N:M sparsity into LLMs to improve both memory and computational efficiency.
Recently, approaches such as SparseGPT and Wanda, utilize a small calibration set and carefully designed importance criteria to identify such redundant parameters. However , two substantial challenges remain: Firstly, the small calibration set is insufficient to represent the comprehensive knowledge embedded in LLMs and Secondly, using handcrafted criteria as a proxy for the true discrepancy inevitably results in errors.
To address this researchers have introduced MaskLLM, a learnable pruning method that establishes Semi-structured (or “N:M”) Sparsity in LLMs, aimed at reducing computational overhead during inference. Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages: 1) High-quality Masks - effectively scales to large datasets and learns accurate masks; 2) Transferability - the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks.
MaskLLM was assessed using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods. For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model’s 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM’s learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains.
Paper : https://arxiv.org/pdf/2409.17481