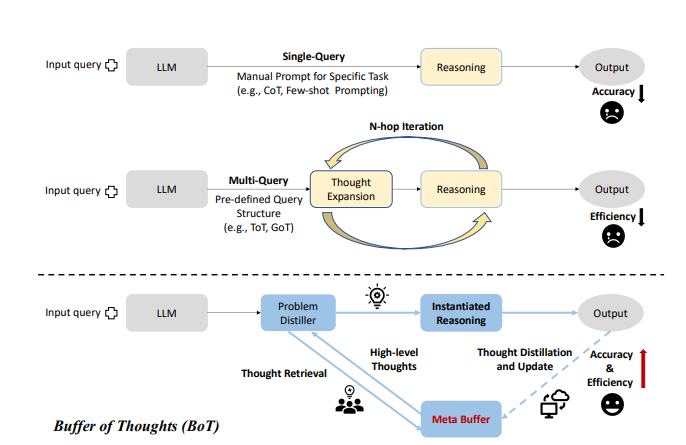
Recently, various prompting methods such as CoT, ToT and GoT have been instrumental in improving reasoning performance of LLMs. All these methods can be broadly divided into two categories:
single-query reasoning: these methods usually focus on prompt engineering and their reasoning process can be finished within a single query, such as CoT that appends the input query with ’Let’s think step by step’ to produce rationales for increasing reasoning accuracy.
multi-query reasoning: these methods focus on leveraging multiple LLM queries to elicit different plausible reasoning paths, thus decomposing a complex problem into a series of simpler sub-problems, such as Least-to-Most ToT and GoT.
However, both single-query and multi-query reasoning processes are limited by their designed examples and reasoning structures, and they neglect to derive general and high-level guidelines or thoughts from previously-completed tasks.
To address these limitations, researchers have proposed Buffer of Thoughts (BoT), a novel and versatile thought augmented reasoning framework aimed at enhancing reasoning accuracy, efficiency and robustness of LLMs across various tasks. BoT uses a meta-buffer, a lightweight library housing a series of universal high-level thoughts (thought-template), which are distilled from different problem-solving processes and can be shared across tasks. Then, for each problem, a relevant thought template is retrieved and instantiated with a specific reasoning structure for efficient thought-augmented reasoning. In order to guarantee the scalability and stability of BoT, a buffer-manager is used to dynamically update the meta-buffer, which effectively enhances the capacity of meta-buffer as more tasks are solved.
During extensive experiments on 10 challenging reasoning-intensive tasks BoT have shown significant performance improvements over previous SOTA methods: 11% on Game of 24, 20% on Geometric Shapes and 51% on Checkmate-in-One. Further analysis demonstrates the superior generalization ability and model robustness of BoT, while requiring only 12% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Notably, it was found that Llama3-8B + BoT has the potential to surpass the Llama3-70B model in reasoning-intensive tasks.
Paper : https://arxiv.org/pdf/2406.04271
Code : https://github.com/YangLing0818/buffer-of-thought-llm