Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. However, despite the plethora of LLMs and their impressive achievements, they still face inherent constraints on model size and training data. At the same time, different LLMs possess unique strengths and specialize in various tasks.
So can we harness the collective expertise of multiple LLMs to create a more capable and robust model?
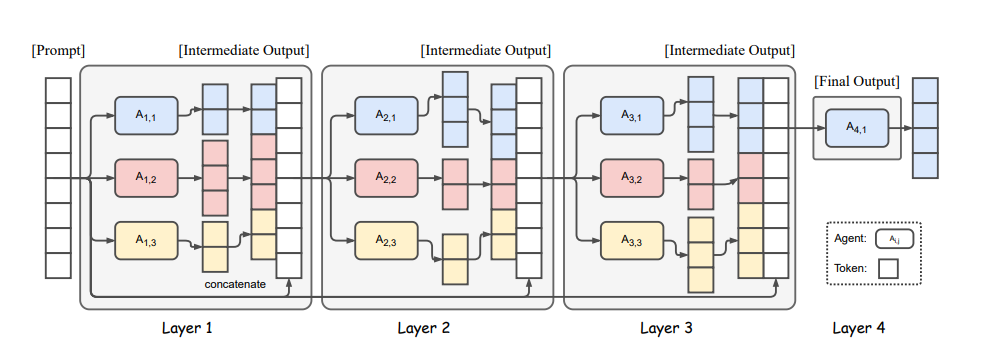
Answer lies in collaborativeness of LLMs — wherein an LLM tends to generate better responses when presented with outputs from other models. Based on these findings researchers have introduced the Mixture Of-Agents (MoA) methodology that leverages multiple LLMs to iteratively enhance the generation quality.
The structure of MoA is as follows: Initially, LLMs in the first layer, let say agents A1,1, …A1,n independently generate responses to a given prompt. These responses are then presented to agents in the next layer A2,1, …A2,n (which may reuse a model from the first layer) for further refinement. This iterative refinement process continues for several cycles until obtaining a more robust and comprehensive response.
To ensure effective collaboration among models and improve overall response quality, careful selection of LLMs for each MoA layer is crucial. This selection process is guided by two primary criteria: (a) Performance Metrics: The average win rate of models in layer i plays a significant role in determining their suitability for inclusion in layer i + 1. Therefore, selecting models based on their demonstrated performance metrics ensures higher-quality outputs. (b) Diversity Considerations: The diversity of model outputs is also crucial. Responses generated by heterogeneous models contribute significantly more than those produced by the same model. By leveraging these criteria — performance and diversity — MoA aims to mitigate individual model deficiencies and enhance overall response quality through collaborative synthesis.
A comprehensive evaluation of the MoA framework was done using AlpacaEval 2.0, MT-Bench, FLASK benchmarks for assessing the response quality across various dimensions. The results demonstrate substantial improvements, achieving a new SOTA win rate of 65.8% on AlpacaEval 2.0 compared to the previous best of 57.5% achieved by GPT-4 Omni.
Paper : https://arxiv.org/pdf/2406.04692