In an era of information overload, manually annotating the vast and growing corpus of documents and scholarly papers is increasingly impractical. Automated keyphrase extraction addresses this challenge by identifying representative terms within texts. However, most existing methods focus on short documents (up to 512 tokens), leaving a gap in processing long-context documents.
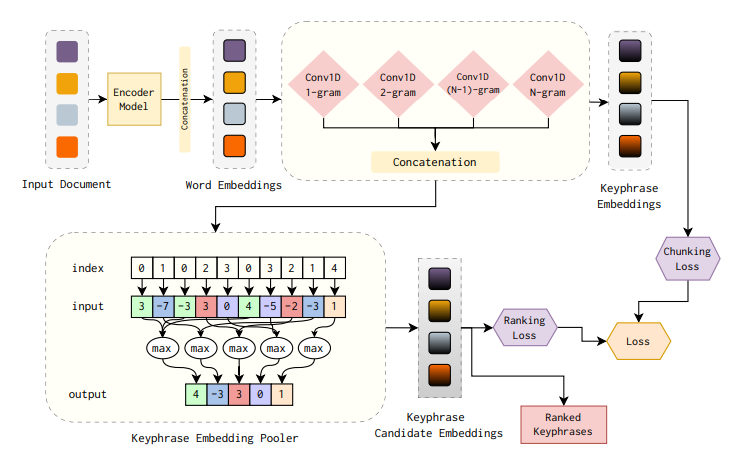
Introducing LongKey, a novel framework for extracting keyphrases from lengthy documents, which uses an encoder-based language model to capture extended text intricacies. LongKey uses a max-pooling embedder to enhance keyphrase candidate representation. LongKey operates considering three stages:
First, Initial word embedding is generated for long documents using the Longformer model, which handles extended contexts through sliding local and global attention mechanisms. It uses a tokenizer based on RoBERTa to convert documents into tokens, which are then processed by Longformer to create embeddings. Large documents are split into chunks of up to 8,192 tokens, and their embeddings are concatenated to form a unified representation.
Second, Keyphrase candidate embedding is context-sensitive, with each word represented by the first token to reduce computation. To create a single embedding for each word, only the first token of the word is used, reducing computational complexity. A convolutional network then generates n-gram embeddings (up to length 5), enhancing keyphrase relevance and ranking. This approach improves the precision and relevance of keyphrase extraction.
Finally, candidate scoring are assigned ranking scores, with higher scores indicating keyphrases that better represent the document’s content. The model fine-tunes performance by optimizing ranking and chunking losses, using ground-truth keyphrases as positive samples and others as negative samples. Linear layers are used to generate ranking scores by converting candidate embeddings into single values.
Validated on the comprehensive LDKP datasets and six diverse datasets, LongKey consistently outperforms existing unsupervised and language model-based keyphrase extraction methods marking an advancement in keyphrase extraction for varied text lengths and domains.